断断续续学习了神经网络许久,今日才正式实践,深感自责,学习激情略显低沉。
对于神经网络,最重要的是理解【神经网络】的抽象化概念,和springcloud类似,都是概念>>代码。(下文都只是我的个人理解,因为才见门路,所以可能部分内容不是严格意义上正确的,甚至有可笑的理解错误,见谅)
在大的层面来看,神经网络可以解决的问题就是从一类已知的特征值序列与目标参量,来对一个新的特征值序列分析目标结果。神经网络可以智能(?智能与否取决于算法,否则大抵只是穷举⑧)推导得到特征值到目标参量的公式,只要给公式赋值就可以得到结果了。那么如何得到这个公式就成了热点话题。从早先的机器学习预测算法,如KNN算法,随机树/随机森林,朴素贝叶斯等都是简单可使用的算法,这种算法相比于神经网络的算法,更有依据可依、简单明了的特征,适当组合其他依据算法,可以处理常见的异常情况,不过也有着明显的缺点,比如不能抽象成一条公式,每次预测都要重新计算训练样本,对于无法直接看出内在联系的特征值结果,总是无从下手。这时候就需要引入神经网络的思想了,神经网络可以不用知道特征值与目标之间的直接关联,只需要程序不断尝试自学习,得到一个损失低又不会过拟合的情形,得到公式即可,相比于传统的机器学习,对数据集的量更加看重,量少的话,往往会偏差很大(没有足够的数据量来支撑公式的可靠性)。
那么神经网络的基本构成是什么呢?
输入层-隐藏层(一层或者多层)-输出层。输入层的数量即特征值数;隐藏层即是公式应用的层,可以通过简单的激发函数(常用relu),对输入层或上层隐藏层的特征值进行加权与偏置(w与b);输出层即最后映射的结果,如果是分类的常用softmax。为了让数据能够自动修正,需要计算第一轮次的损失值(crossentropy交叉熵,有categorical多分类以及binary二元分类),计算当前公式矩阵组在不同位置的梯度,对矩阵组调整,进行梯度下降,让整体的损失值逐渐减少(也可能会反弹,可能是降梯过度,绕过了梯度最低点)。梯度的计算方式可以采用微分法计算,取小变化量h,计算损失差值,一般取当前矩阵变量值x0±h来算梯度,h的大小选择也会影响到结果的可靠性,如果h太大,可能直接跳过了整个域的最低点,如果太小,难以感知到大的梯度变化,需要更多的轮次来调整,增加了运算成本。
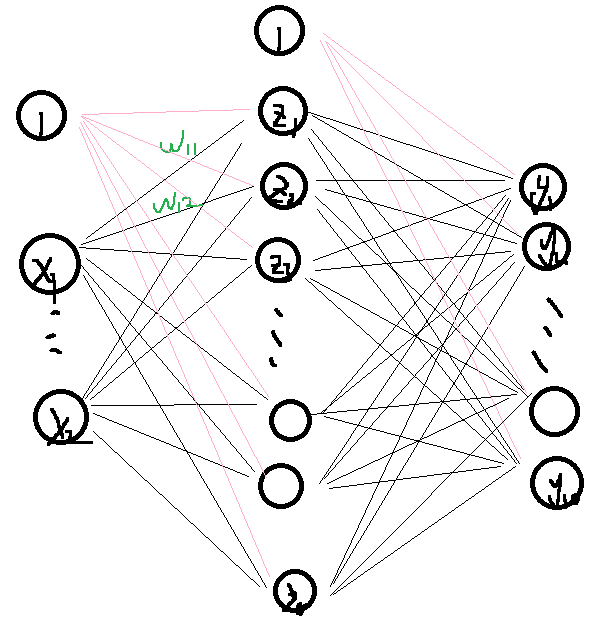
输入层-隐藏层(一层)-输出层
又因为训练用数据集通常很大,直接载入的话,对于单次运算需要消耗的资源太大,对系统是个负担,甚至可能跑不动,要得到结果必须完整跑完,无法充分应用cuda算力等问题。所以对于训练集我们通常需要分批求损,最终再汇总得到结果,这样的好处是随时可以停止,保存临时的训练结果,以供下次继续恢复训练,同样可以利用cuda,让训练更加迅速。
训练的核心公式:Z= active(XW+B)
当然了,上面的解释只是讲述的底层,而对于神经网络,一般的流程是泛用的(除非有定制化需求),可以直接使用tensorflow工具来构建神经网络(安装tensorflow工具来操作神经网络pip install tensorflow)。数据集mnist可以官网下载到本地。
下面是对mnist手写数字集的训练代码,将训练结果保存到了文件,以供下次预测直接使用。
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import to_categorical
import numpy as np
data = np.load('../mnist.npz', allow_pickle=True)
x_train = data["x_train"]
x_train = x_train.reshape(len(x_train), 28 * 28)
x_train = x_train.astype('float32') / 255
y_train = data["y_train"]
y_train = to_categorical(y_train)
x_test = data["x_test"]
x_test = x_test.reshape(len(x_test), 28 * 28)
x_test = x_test.astype('float32') / 255
y_test = data["y_test"]
y_test = to_categorical(y_test)
# 初始化神经网络
model = Sequential()
# 添加一个有64神经元的隐藏层
model.add(Dense(64, activation='relu', input_shape=(28 * 28, )))
# 添加输出层
model.add(Dense(10, activation='softmax'))
# 编译模型
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=5, batch_size=128)
# 评估模型
loss, accuracy = model.evaluate(x_test, y_test)
print('test_acc:', accuracy)
model.save('num_anz.h5')
然后下面是应用训练结果预测的测试代码:
import numpy as np
from keras.models import load_model
loaded_model = load_model('num_anz.h5')
data = np.load('../mnist.npz', allow_pickle=True)
x_test = data["x_test"]
x_test = x_test.reshape(len(x_test), 28 * 28)
x_test = x_test.astype('float32') / 255
y_test = data["y_test"]
predictResults = loaded_model.predict(x_test[0:5])
print(y_test[0:5])
for idx in range(len(predictResults)):
print(np.argmax(predictResults[idx]))
虽然只用了一层隐藏层,并且隐藏层只有64个神经节点,预测的成功率也达到了96.8%。当然,目前用的测试用例都是数据集里的,后续需要自己写一个工具,来生成自己的手写字来检查是否真正有效。还要测试图片背景不是纯白色(即背景灰度值非0)的情况下,是否能成功预测出来,目前来看这个训练集都是背景纯白色的手写字,对泛用性持怀疑态度。
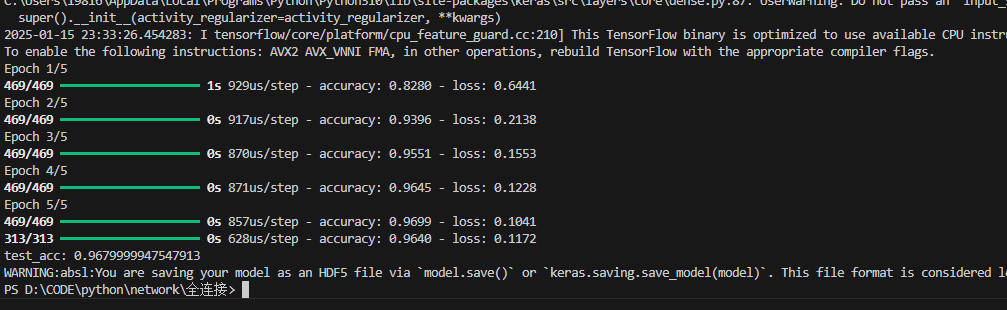
训练与测试集的预测准确率计算结果