在六月,兴致冲冲的买了各种配件,自组了一台电脑(等等等等,我貌似还没在博客说过这个事,先简单描述下,4060Ti16G + 12600KF)。最开始的几个月还是很有激情的,下了各种游戏,直接把画质拉到最高,玩起来就叫一个爽字,然后还下了很多4K视频看,对很多番剧进行插帧与分辨率提升,跑AI模型、批量剪辑与特效制作......把所有此前想做却无法实现的需求,全都一一体验,已经渐渐失去兴致了,最后导致现在、打开电脑——音乐播放器ON。
(下图,是当时按捺不住激动的心情拍下的一张照片)

现在就一直在想,怎么让显卡能发挥作用呢?游戏也就那些日复一日的角色养成游戏,完全发挥不了RTX4060Ti的价值啊,所以就将思维转到显卡的作用上——对简单重复的计算能够快速的处理。那么,我又何尝不能直接去利用显卡的优势,去做些程序呢?
通过一系列的百度搜索、b站搜索,就找到了这样的一个概念:CUDA编程。CUDA编程,是针对N卡所特有的编程支持,可以直接将计算放在N卡上去跑。相对的,对游戏minecraft(我的世界)光影熟知的小伙伴肯定也听过OpenGL,其实openGL也是利用显卡进行图像绘制的支持,相比于CUDA不同的是,OpenGL是跨平台的,不管是A卡还是N卡都可以通过openGL来实现显卡的调用,但是与此带来的代价就是,可能无法完全发挥N卡的性能且无法完全利用N卡特性。当然,与OpenGL(Graphics图像)一起的还有OpenCL(Computed计算)、OpenAL(Audio音频)支持,都有各自擅长的领域。
我们都知道的是CPU是计算机的核心,在历史上一直都是最受关注的计算机组件,而随着AI技术如雨后春笋般涌现,GPU逐渐步入大众视野,甚至有可以比肩CPU地位的势头。作为如今计算机必不可少的两个组件,他们各自有着自己的职责,CPU负责各种乱七八糟的任务调度处理,是一个总体有序的精密组件,他独自掌握着丰富的能力,坐着计算机大当家的位置,现在的计算机核心数也变多了,间接的提升了CPU的效率,虽然很多软件的设计还是一核有难多核围观的局势。GPU仔细看,更像是血汗工厂,大量的ALU(计算)单元,遵从所在Control(控制)单元的指令利用仅有的一点点Cache(缓存)来做着简单的数据计算,主打一个能力不够,量大管快。
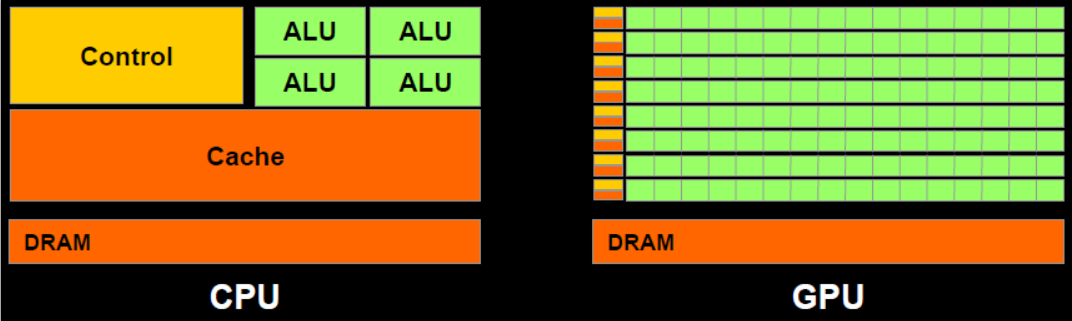
因为控制单元和缓存单元相比于CPU来说小很多,所以,对于一些复杂的指令和任务更适合放在CPU中去跑,而一些量大的简单指令更适合放在GPU上跑。我们注意到GPU自己也是有Cache缓存的,我们CPU处理的原始数据如果要放在GPU进行处理的话,那么需要先将CPU中的数据写入到GPU中,在GPU中计算并且保存在GPU的缓存中,最后由CPU读取GPU的Cache写回CPU中。
在程序设计层面,GPU任务被拆分成Grid、Block、Thread,一个Grid下有多个Block,一个Block下有多个Thread。与硬件上的关系就是,Thread对于CUDA核心即SP,Block对应SM大核,Grid对应Device。
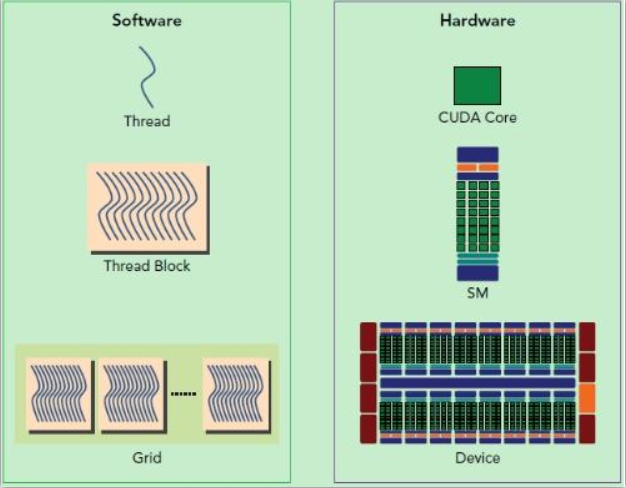
对于GPU编程,一个比较重要的地方是,获取当前核心执行的位置,如果是一维数组处理,位置就是: blockIdx.x * blockDim.x + threadIdx.x . 其中blockIdx指当前所在块位置,threadIdx指当前所在线程位置,blockDim表示单个块的分配大小。这种定位方式其实就按照多维数组降维来理解就可以了。先找到当前块前面几个块的总线程数,再找当前所在块经过的线程数,就定位到当前位置了。
编程实现,我这里使用C++作为语言载体来设计实现。
对于OpenCL的实现方式,也有尝试过,需要先去github的微软用户下下载OpenCL的代码,之后引入CL的头文件,因为本文主要介绍CUDA编程,所以OpenCL我只简单写个基础流程:第一步,找到平台platform;第二步,找到指定设备device;第三步,获取当前设备的上下文context;第四步,创建队列queue;第五步,获取程序programSource;第六步,编译程序program;第七步,创建与设置出入缓存buffer;第八步,放入program执行程序;第九步,数据写回内存;第十步,释放资源。
接下来是重点,通过一个简单的案例来演示如何进行CUDA编程。
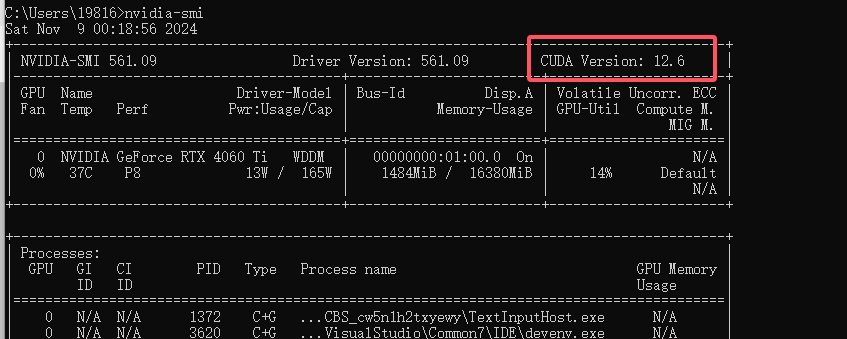
首先是环境准备,我们需要先运行如下指令,来查看当前显卡支持的CUDA版本。
nvidia-smi 可以得到类似下图的结果,可以看到我电脑支持的CUDA版本是12.6.
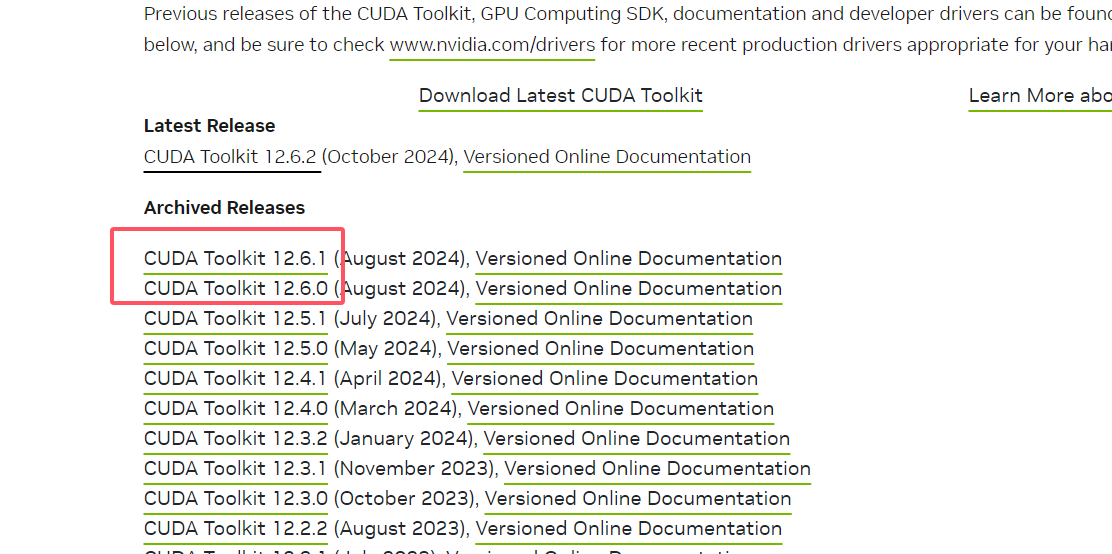
接着需要到官网(https://developer.nvidia.com/cuda-toolkit-archive)下载Cuda Toolkit,选择对应的版本。后续选择平台windows => x86_64 => 10/11 => exe(local)。安装时选择精简安装即可,我因为安装过了,就不再重新安装了。切记,在安装之前先安装visual studio嗷!
安装成功之后,我们需要手动增加两个环境变量,后续指令要用(环境变量还不会配置的自行百度吧~)。一个CUPTI的lib64目录(程序执行可能报错缺少cupti64.dll),一个是ns工具目录(cuda程序GPU执行信息,配置好后,运行 nsys 应该会有指令提示)。默认安装路径和我这个应该差不多。
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.6\extras\CUPTI\lib64
C:\Program Files\NVIDIA Corporation\Nsight Systems 2024.4.2\target-windows-x64 等环境都配置没问题后,我们打开visual studio,新建cuda项目(如果cuda toolkit正确安装了,应该会显示这个项目)。一直下一步。
项目自动构建后,会自动创建一个kernel.cu的源文件,对于cuda编程的文件后缀都是cu。
我们先写一个最简单的程序,功能是生成2^20组数,每组数都是1.0f和2.0f,我们要计算每组数的和,并且校验是否有计算错误的数据。在这个示例中,我们采用的是一维数组,并且只有一个block,每次一个thread,相当于一个一个执行。编写完成,保存后,点击执行即可得到结果 Max error: 0 了。
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <iostream>
#include <math.h>
// Kernel function to add the elements of two arrays
__global__
void add(int n, float* x, float* y)
{
int index = threadIdx.x;
int stride = blockDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1 << 20;
float* x, * y;
// Allocate Unified Memory – accessible from CPU or GPU
cudaMallocManaged(&x, N * sizeof(float));
cudaMallocManaged(&y, N * sizeof(float));
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 1M elements on the GPU
add << <1, 1 >> > (N, x, y);
// Wait for GPU to finish before accessing on host
cudaDeviceSynchronize();
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i] - 3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
cudaFree(x);
cudaFree(y);
return 0;
}
// nsys profile --stats=true CudaRuntime1.exe 接着,我们来到编译生成的目录下,执行如下指令 nsys profile --stats=true CudaRuntime1.exe ,得到如下结果。可以看到,总计耗时 455209747 ns,即 455ms,还是比较慢的。
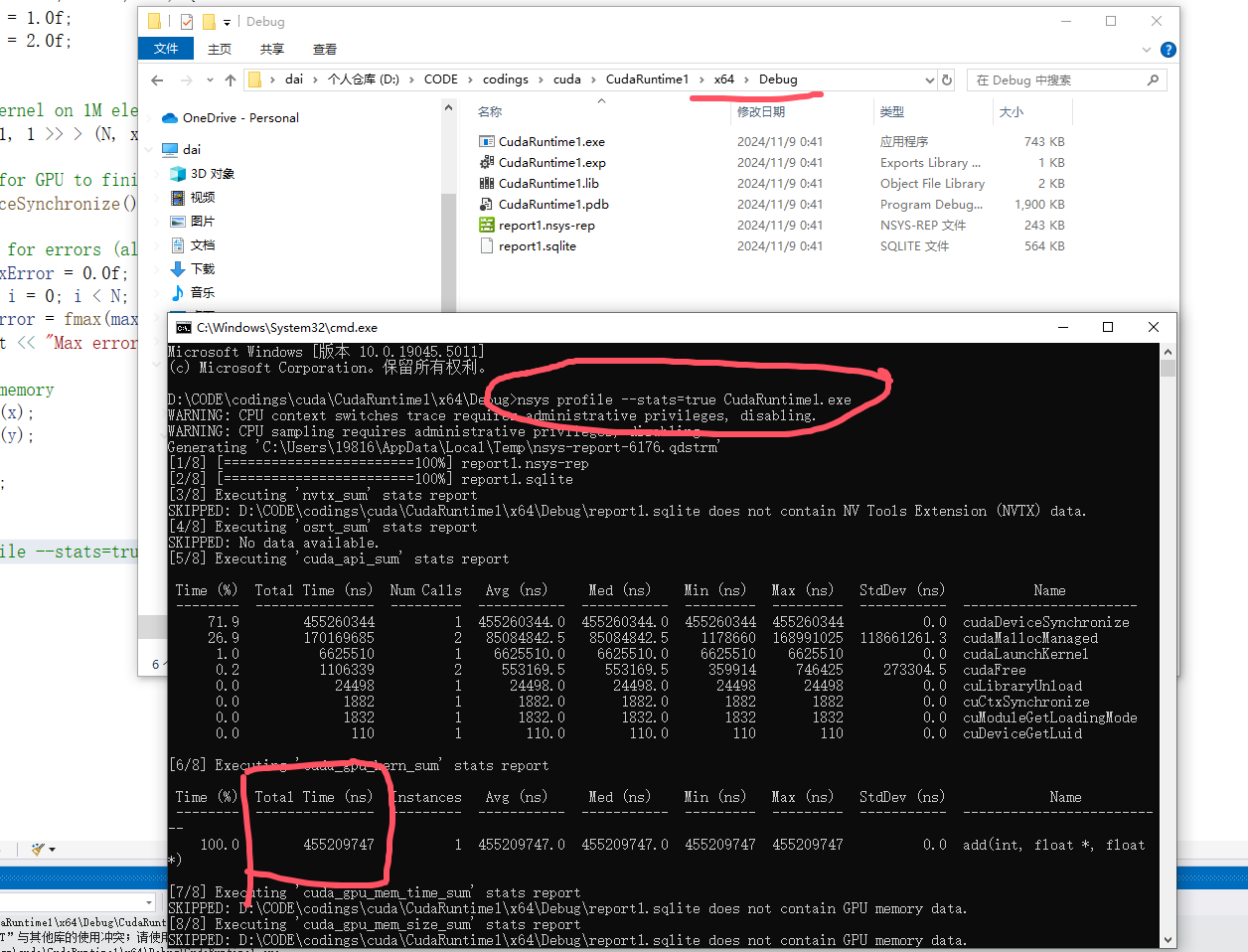
我们尝试将 add << <1, 1 >> > (N, x, y); 改成add << <1, 256 >> > (N, x, y); 即一个块256线程,重新生成exe文件后再nsys分析,发现速度快了很多,只用了2488846ns,即 2ms,快了两百倍!

当然聪明的你一定发现了,我上面都只用到一个块,如果增加块数呢,会快多少呢,将代码改成如下。其中numBlocks表示处理完这N组数据,至少需要多少组。
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <iostream>
#include <math.h>
// Kernel function to add the elements of two arrays
__global__
void add(int n, float* x, float* y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = gridDim.x * blockDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1 << 20;
float* x, * y;
// Allocate Unified Memory – accessible from CPU or GPU
cudaMallocManaged(&x, N * sizeof(float));
cudaMallocManaged(&y, N * sizeof(float));
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 1M elements on the GPU
int block_size = 256;
int numBlocks = (N + block_size - 1) / block_size;
add << <numBlocks, block_size >> > (N, x, y);
// Wait for GPU to finish before accessing on host
cudaDeviceSynchronize();
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i] - 3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
cudaFree(x);
cudaFree(y);
return 0;
}
// nsys profile --stats=true CudaRuntime1.exe 我们再尝试nsys一下,看看效果怎么样。
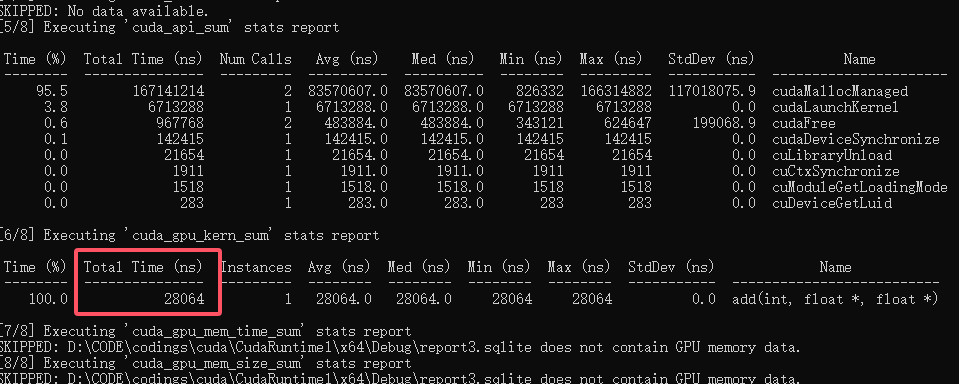
28064ns!![[[厉害了]]](https://www.dreamcenter.top/emoji/lhl.jpg) 只用了28us,相比于最开始的455209747ns,提速了16220倍!足以可见显卡的对于这种数据处理的效果之强大!至于二维的计算,暂且还没研究哈,等后面有机会再研究研究二维的。
只用了28us,相比于最开始的455209747ns,提速了16220倍!足以可见显卡的对于这种数据处理的效果之强大!至于二维的计算,暂且还没研究哈,等后面有机会再研究研究二维的。
话说有没有小伙伴也想尝试的,看看你的卡同样的程序能跑进多少ns![[[搓搓搓]]](/emoji/ccc.gif) ,我4060Ti16G是 28064ns 嗷!
,我4060Ti16G是 28064ns 嗷!