当今时代,数据已经成为了最珍贵的资源之一,我们常常需要为独占数据付出高昂的费用。为了应对这些高昂的数据获取费用,出现了各种工具来实现数据的“攫取”。
本次尝试的是最常见的一种数据获取方式——爬虫。研究这个的起因是近期对一个老的概念很感兴趣,即RSS(Really Simple Syndication),虽说是上个世纪提出来的东西,又因商业化时代而逐渐退出主舞台,于我而言,其真的是反抗现在推荐机制的一个绝佳方案!具体的RSS技术会在以后的文章中介绍,本次主要是解决当今时代RSS的一个痛点,即绝大部分网站都已经不支持RSS了!
当然了,现在也有一些开源软件,提供了现在一些主流网站的RSS代理,如 RSSHub ,但是还是无法覆盖全部的需求,而且自定义的话规则比较复杂,所以并没有去采用。本次采用的是Selenium技术来进行网页的数据抓取,当然达到这个结果不是一蹴而就的,起先是准备直接去各个平台获取数据请求进行调用的,但是有的网站是直接SSR后端渲染页面数据的,有的是请求有复杂的校验机制,所以这个方案直接放弃,也想过直接请求指定网页数据,但是现在大部分的网站都是单页式网站以及异步获取数据,故而无法达到理想的目标,所以就在百度搜索了“如何使用java获取网页加载后的页面数据”,推荐给了我这个 Selenium 数据采集工具。
Selenium工具官网
Selenium,起初只是一个Web应用的自动化测试工具,但是其功能也恰好重合于爬虫的需求,逐渐在爬虫领域也有了些许地位,目前他不仅支持java语言,同时也支持了 .Net/C#、Ruby、Python、JS 这些主流语言。实现网页数据获取的原理大抵上也就是调用特定浏览器的驱动,来打开一个网页,然后从网页获取整个dom结果树,有了dom树,当然就可以对dom节点进行各种js操作了。
本文使用的是 Java语言 + Chrome浏览器 进行的开发。其他语言和浏览器基础原理也大抵相似。
前置准备-下载浏览器驱动
开发前置准备,是要获取对应的本地浏览器驱动,我当然是以作为最受开发者信赖的chrome浏览器来进行开发。如果你的本地谷歌浏览器恰好是最新的浏览器,可以从 谷歌测试驱动 网站找到对应个人系统版本的驱动程序。如果自己本地谷歌浏览器版本较低,可以参考这个github仓库: chrome-for-testing ,所有适配不错的版本有列出在这个json文件中:known-good-versions-with-downloads.json 。 当然如果你习惯使用edge,可以参考这个地址下载:Edge驱动下载地址 。其他的我就不一一列出了,在各自的官方网站应该都能找到,或者直接问AI也能给到你答案。
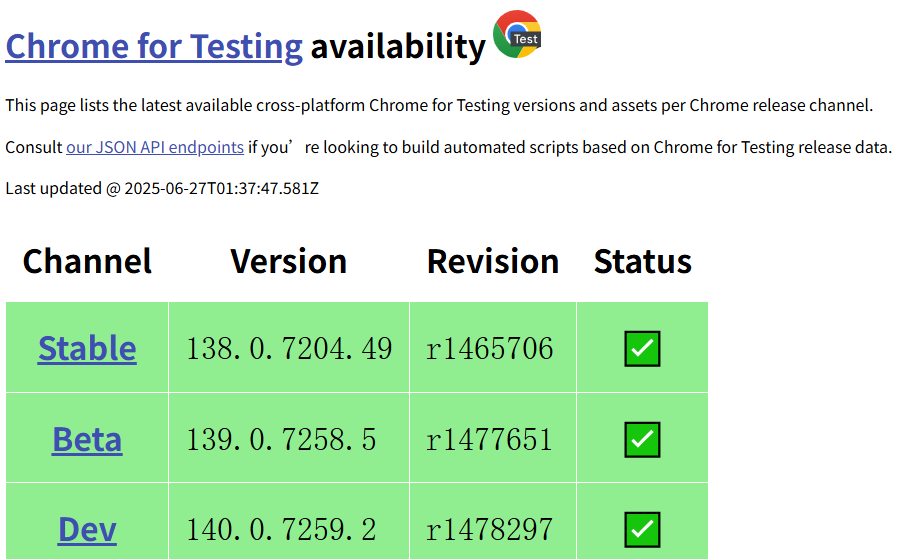
较新的驱动程序
现在跟着我一步一步下载谷歌的驱动。
首先是打开自己谷歌浏览器的设置页面,查看本地谷歌浏览器的版本号。比如我这里是【版本 138.0.7204.50(正式版本) (64 位)】。
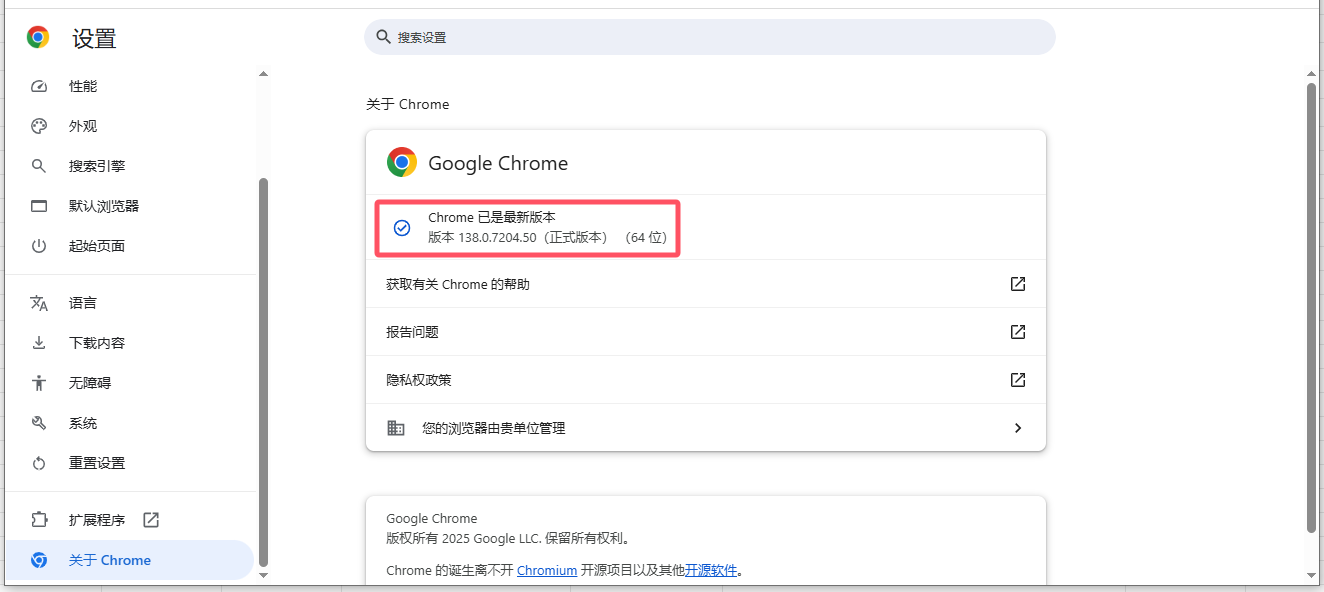
本地谷歌浏览器版本号
接着从官网驱动列表下载对应大版本的驱动程序,大版本下的驱动兼容性不会出现太大问题。我这边大版本是 138.0.7204,从json列表可以找到距离我小版本50最近的一个版本只有49.
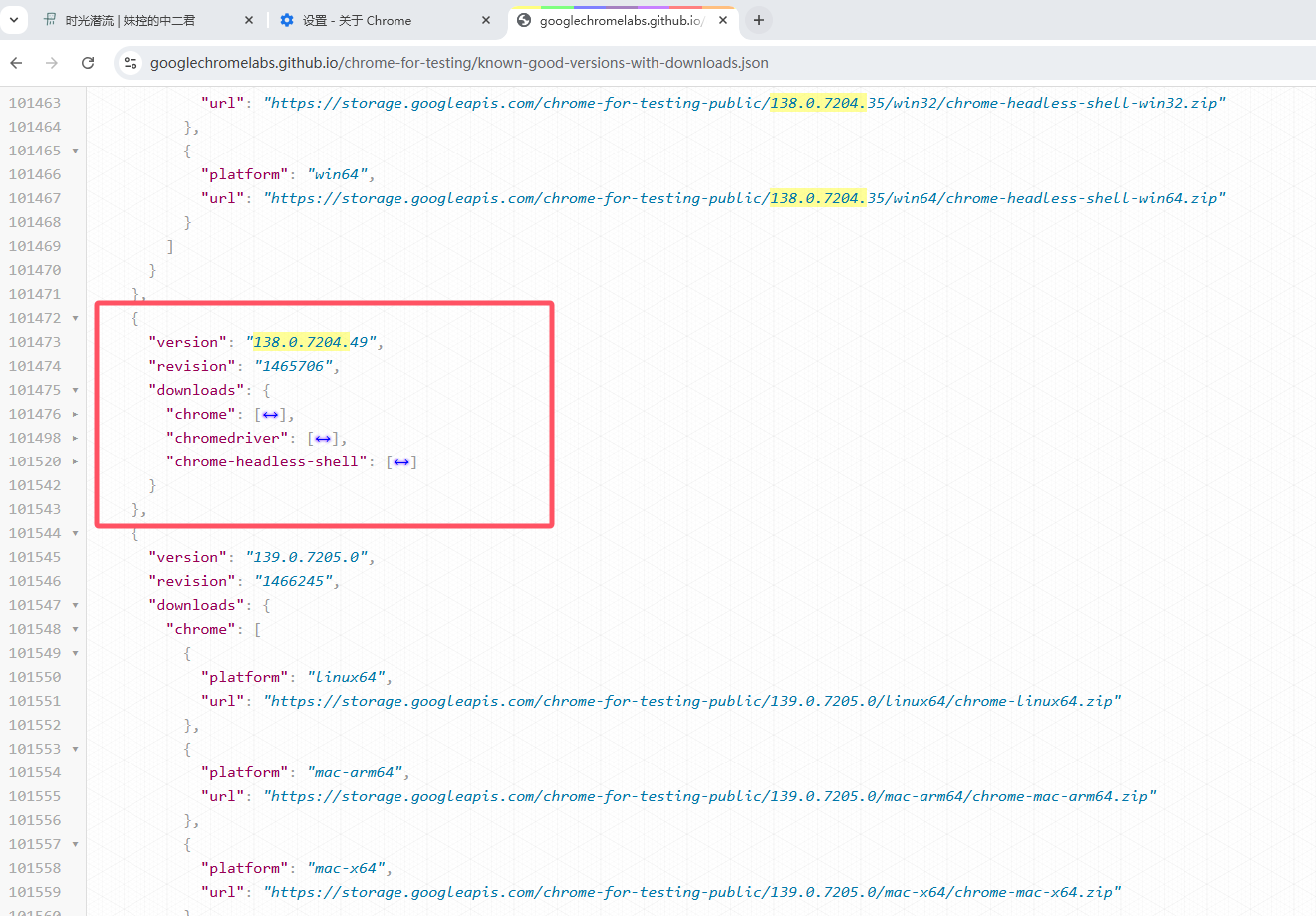
找到对应的版本号
对于google浏览器的downloads这里提供了三个下载大类,chrome 表示浏览器本体,chromedriver 表示浏览器的驱动程序,chrome-headless-shell 表示无头浏览器容器。我们这里要选择driver驱动列表,我的浏览器是win64版本的,所以也选择对应的驱动下载。

下载chrome-win64驱动
下载完毕,解压到自己的某个文件夹中。应该会出现下面三个文件,一个是驱动程序本体,另外两个是相关协议和三方说明。个人建议将所有的驱动都统一管理于某个文件夹下,方便日后查找。
解压驱动压缩包
至此,我们驱动就已经准备就绪了。
程序设计
我这边以java为示例,其他的语言参考主要逻辑即可。
引入selenium的依赖包。核心的依赖包如下。
<dependencies>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.1.2</version>
</dependency>
</dependencies>接下来必要的第一步是设置驱动程序位置到环境中,设置系统环境变量 webdriver.chrome.driver,值为自己的驱动程序完整路径。
System.setProperty("webdriver.chrome.driver", "D:\\tools\\jars\\chromedriver-win64\\chromedriver.exe");然后我们需要设置浏览器的一些配置参数,不同浏览器可能有些许不同。google这里我设置了两个参数,允许所有源 & 无头执行(后台执行),如果你想要看到浏览器加载的完整过程,则不用加headless。将这下参数加入到对应浏览器的Driver构造器中,谷歌就是ChromeDriver,Edge就是EdgeDriver。
ChromeOptions options=new ChromeOptions();
options.addArguments("--remote-allow-origins=*");
options.addArguments("--headless");
WebDriver driver = new ChromeDriver(options);先实现一个最基础的功能——打开一个网页,并且获得该网页的标题和内容。使用get函数即可发起调用,等到加载完成后,getTitle可以获取到当前活动页签的标题,getPageSource获取完整的文档内容。
try {
// 打开网页
driver.get(url);
String title = driver.getTitle();
String pageSource = driver.getPageSource();
System.out.println(title);
System.out.println("==================================");
System.out.println(pageSource);
} finally {
// 关闭浏览器
driver.quit();
}我这里调用一位友链的博客网站,可见全部成功获取了。
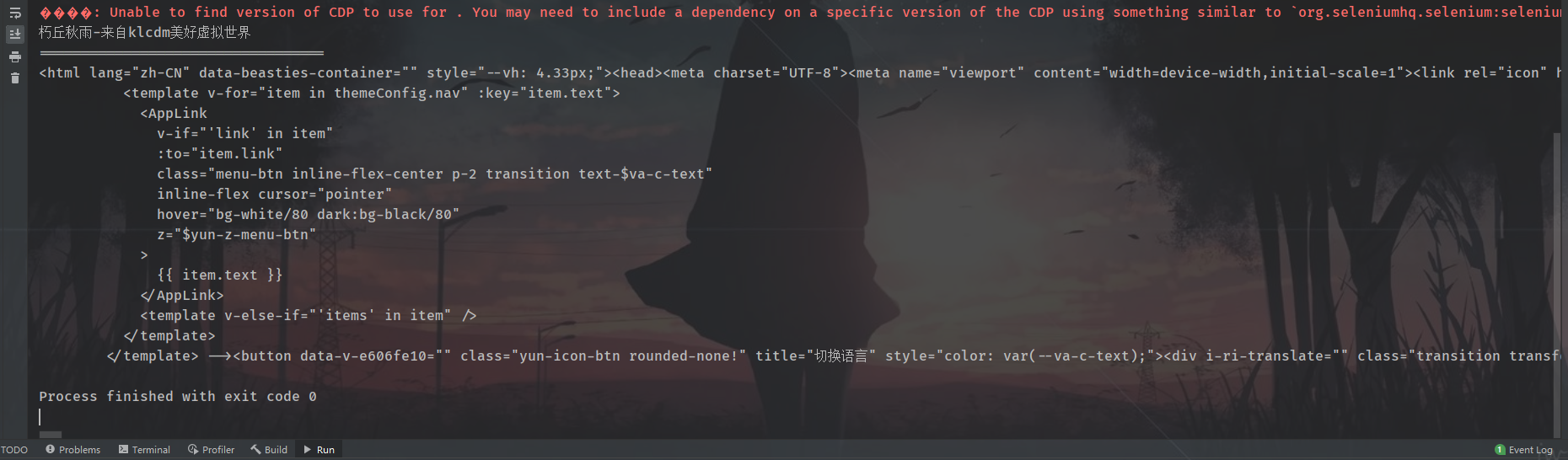
获取友链标题首页数据
当然我们实际的数据挖掘不可能硬啃这个结果文档字符串,selenium 的强大之处就是可以获取dom节点进行处理。其使用方式和js的元素探查方式一致,如 findElement/findElements 查找一个或者多个元素,参数类型By,表示依据什么选择器进行元素选择,比较通用的就是By.cssSelector(),和 js 的 document.querySelector(...) 类似,可以写一串css的选择器来定位到特定的节点。
如果要对博客进行RSS解析,比较关键的几个属性就是:标题、日期、概述。所以封装一个简单的函数,来调用某个博客的文章列表。需要传递的参数:boxSelector即选择单篇博客的最大盒子,titleSelector选择标题节点,time选择时间节点,contentSelector选择内容节点。
private static void caller(String url, String boxSelector, String titleSelector, String time, String contentSelector) {
//访问限制处理
ChromeOptions options=new ChromeOptions();
options.addArguments("--remote-allow-origins=*");
options.addArguments("--headless");
WebDriver driver = new ChromeDriver(options);
try {
// 打开网页
driver.get(url);
System.out.println("=================" + url + "===================\n");
List<WebElement> blogs = driver.findElements(By.cssSelector(boxSelector));
for (WebElement blog : blogs) {
String title = blog.findElement(By.cssSelector(titleSelector)).getText();
String date = blog.findElement(By.cssSelector(time)).getText();
String content = blog.findElement(By.cssSelector(contentSelector)).getText();
System.out.println(date + " " + title);
System.out.println(content);
System.out.println();
}
} finally {
// 关闭浏览器
driver.quit();
}
}这样,如果我要查看一个博客的文章列表,只要如下简单配置调用即可(我这里以友链 朽丘秋雨 的博客为案例)。
caller("https://blog.koxiuqiu.cc/", ".yun-card", ".title span", ".posted-time time", ".markdown-body");调用结果如下图所示:

友链博客获取测试
因为这种封装结构对任何博客都有效,所以后续可以进行动态修改这五个参数,来实现适时的调整,具有着通用性。当然不仅是对于博客抽取有效,这种格式也可以适用于任何有发布时间的列表数据采集。比如B站某个UP主的视频更新想要推送,也只要获取视频页的时间、标题、封面即可。
小练习-获取B站UP主视频列表
下面是以B站UP主(我自己)视频更新示例的效果。
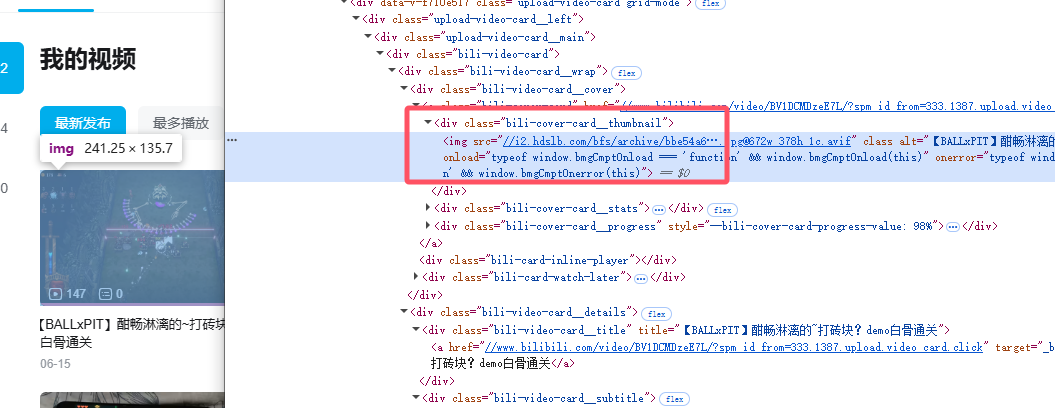
首先F12,查看视频盒子所在元素。可以看到当个视频的盒子的class是“upload-video-card”,选择元素是“.upload-video-card”。
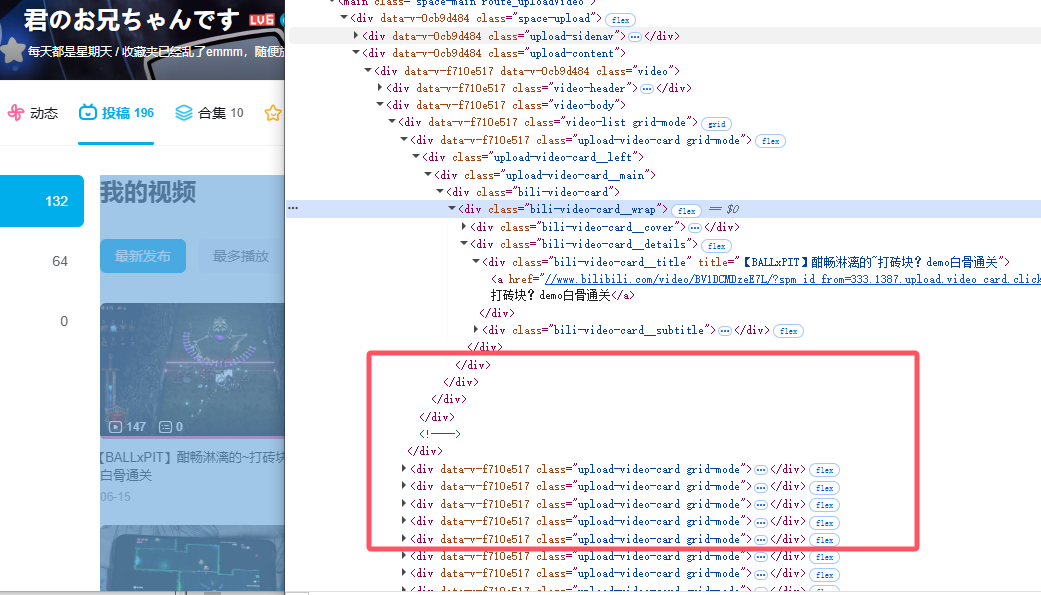
接着查看标题,上级div的class是 “bili-video-card__title”,取其下a链接的文本,即选择元素为“.bili-video-card__title a”。
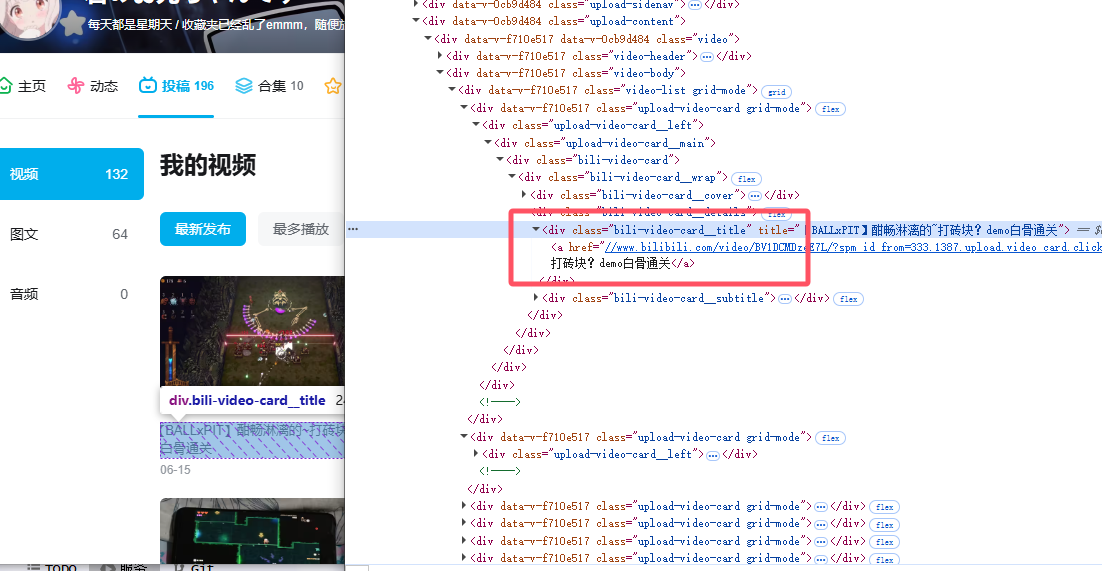
然后是发布日期,取“bili-video-card__subtitle”下的span标签值,即“.bili-video-card__subtitle span”
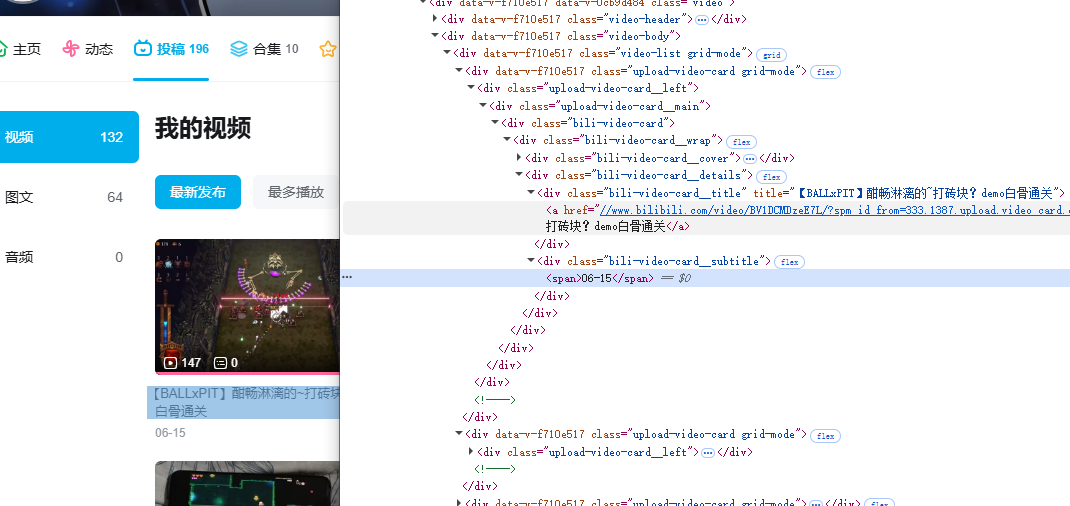
因为没有描述,内容字段就取封面,我们直接取“.bili-cover-card__thumbnail”的内容即可。
所以最终的调用方式如下:
caller("https://space.bilibili.com/39403246/upload/video",
".upload-video-card",
".bili-video-card__title a",
".bili-video-card__subtitle span",
".bili-cover-card__thumbnail");实际效果却并不如人意,感觉是跑的太快了,实际页面并没有渲染完成,驱动就指示我们完成了。

我们在获取节点前先暂停个几秒,让页面完全渲染出来,加上暂停 5s 。
TimeUnit.SECONDS.sleep(5);再次调用,发现成功获取了!
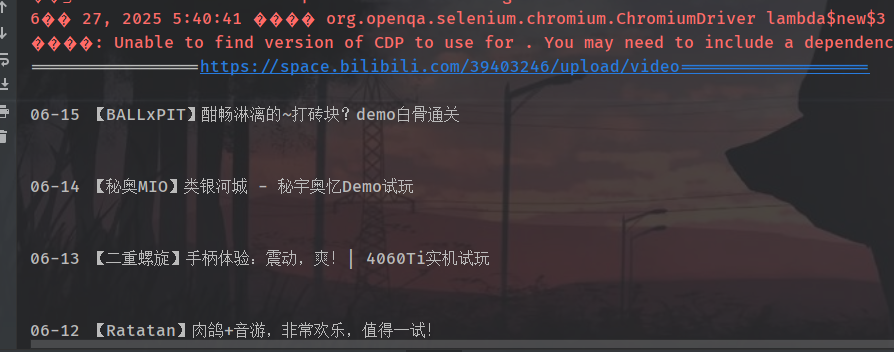
当然了,这些只是能够正常的获取到了我们想要的页面数据,接下来则是利用该方式来构建RSS文档结构。这个在后续再探讨啦!