今天很高兴的是网站已经正式被收录啦,并且解决了一些大大小小需要改善的问题。先从简单的说起,
路由跳转catch
对于vue,我们已经知道路由的跳转有hash和history的两种方式,而对于history模式,服务器的容器需要配置错误页到index页面,这样我们就可以不带#来实现访问,看起来更像一个通用的路由模式。我们在手动进行路由跳转的时候也会使用$router.push(''),然鹅之前没有追加写上catch的习惯,所以每次刷新一些直接带手动跳转的页面时,在console会先报出404未找到的错误,虽然不影响正常访问,但有时还是会给自己带来误判错误的可能性,所以推荐的是每次push后都追加catch,即:
$router.push('').catch(err => err) 这样之后就不会报找不到的错误啦!
数据聚合
之前在后台的数据一览页(各种服务器及网站的状态信息),获取各个状态的方式是多个请求!
这个问题的缺点就是进行了太多次的请求连接与数据响应,在联想到浏览器与服务器每一次的数据交换是基于传输层TCP协议进行的,势必造成网络利用率降低,大量的包装数据占据了主体,而每一个请求所需要的结果所需要的甚至不到100B。
所以采用数据聚合的方式来提高通信利用率,所以这次对每个状态信息在服务端进行汇总,然后合并成一个大的数据体,又因为状态信息可以用int状态进行简单的描述,所以封装成的类型为Map<String,Interger>,其中String是描述的当前数据是什么。
@Override
public RetResult<Map<String, Integer>> getAllInfo() {
Map<String,Integer> map = new HashMap<>();
String visits[] = {"vDynamic", "vBlog", "vAlbum"};
for (String temp: visits) {
map.put(temp, getIntegerInfo(temp).getData());
}
map.put("doge", getDogeStatus().getData());
return RetResult.success(map);
}图片删除逻辑更正
之前的图片删除,只删除了数据库中的记录,其它的方面什么都没有去管。然而事实上图床和本地的图片文件都是要删除的,所以这次对删除业务进行了简单的完善与逻辑更正。删除顺序是对添加的栈逻辑,即先进后出,正好和添加的顺序相反。也就是,现在是先删除数据库记录,然后删除图床,最后删除本地。本地始终是保存最久的。并且是最不活跃的,惰性最大。
百度搜索SEO
基础设置
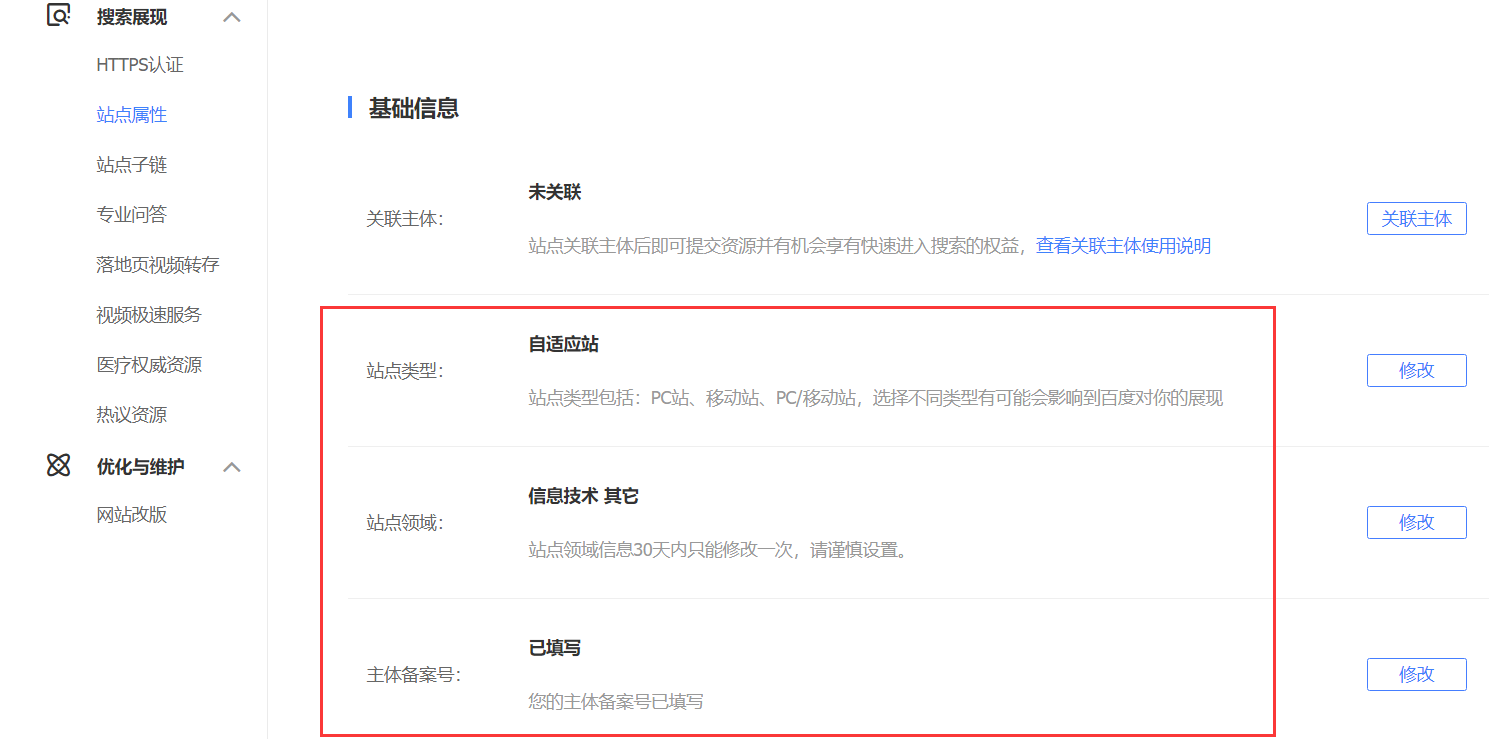
首先要设置好自己站点的领域信息,以及主体备案号(据说设置了收录的更快)。如果网站是https的,还需要认证以下https(这个很快,一天就认证好了)。
其次一定要设置对站点类型,否则就可能出现PC能检索到而手机检索不到的情况产生。我这里采用的是自适应站,因为我的网站是前端依据浏览器宽度来自适应的。大家则需要根据自己的实际情况进行调整,比如pc手机分站模式的、纯pc或者纯手机的等等。
收录方式的选择
目前百度提供了普通收录和快速收录。我只做了普通收录,所以,对于快速收录不做描述。
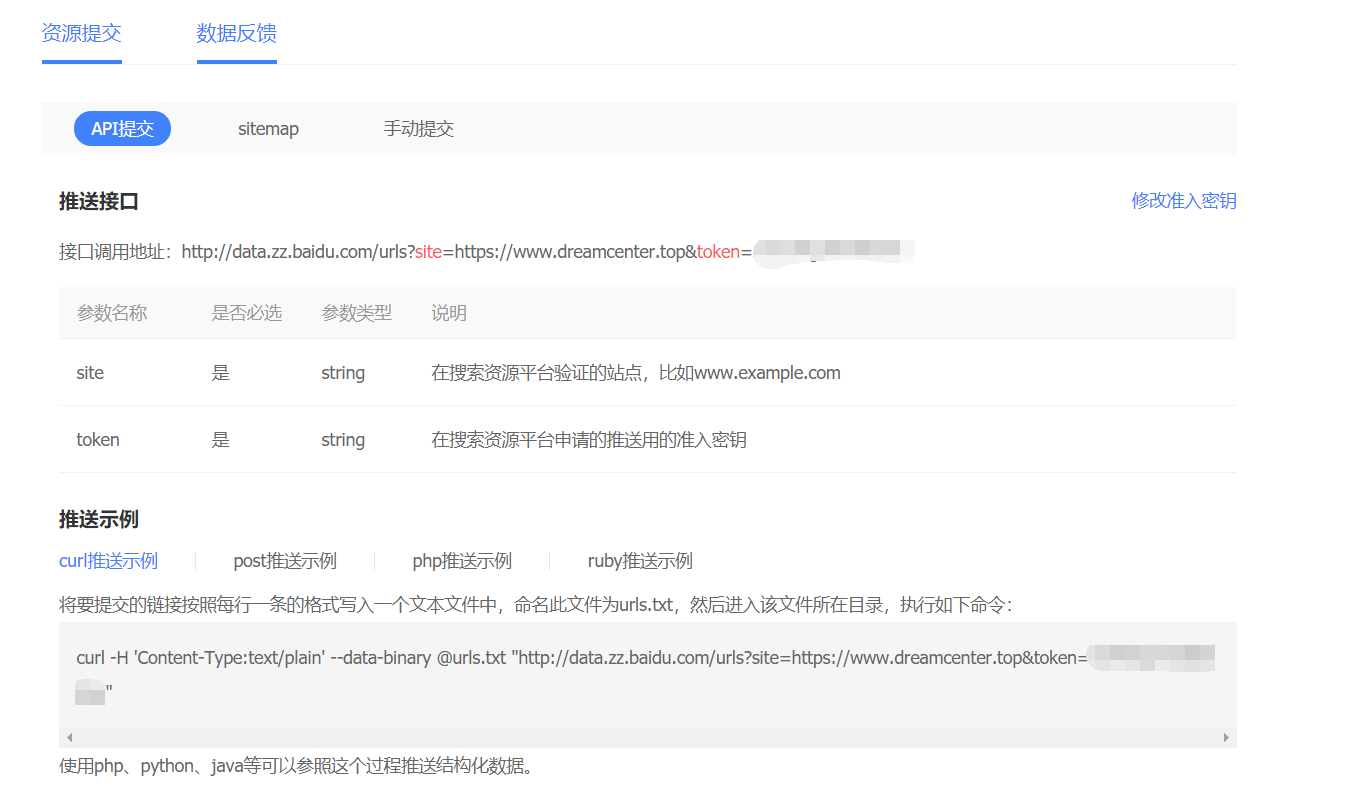
这里又提供了三种提交方式,我采用了第一个API的curl方式提交,该请求需要一个请求体,对于curl方式,-H添加请求头,使用--data-binary可以设置请求体,这里的@urls.txt也就是当前目录下存储的urls.txt文件数据(记录了需要收录的urls)。
执行这条指令后就可以推送了。当然由于这句话不会有什么变化,所以可以写个bat批处理文件(别忘记了加上pause等待几秒来查看是否推送成功!)
敬候佳音
等到提交后,大概过个一周左右就可以被抓到啦!之后就可以通过关键词来搜索到自己的小破站啦!嘿嘿,如果自己的关键词是别人从来没用过的,那么SEO排名第一不是梦*★,°*:.☆( ̄▽ ̄)/$:*.°★* 。
后面大概会去处理一些数据与安全方面的工作吧,目前有点累,想休息一段时间(好像前几篇博客也说了同样的话emmm,但是热情太高了)。之后大概会去准备准备面视的各种题目,回顾一下算法知识,如果可以的话,说不定秋招还能碰碰运气,嘿嘿!下次见!