每每我打开微信的时候,简单翻看着公众号列表,总是会被精准推送到我感兴趣的内容。
什么内容?请看:
那当然是摄影技术研究的内容![[[八嘎]]](/emoji/bg.jpg) 。这么多优秀的拍摄构图!光影!还有思路!非常值得学习。但是每次只是收藏,在下一次查看的时候还要点开收藏,翻阅收藏记录,点击查看文章,步骤过于繁琐,而且还有不感兴趣的文字描述和广告,严重影响了我的学习专注度!!!为了提高学习效率,我就一直想着怎么自动把图片保存到本地进行管理,还希望能同步到服务器进行随时随处学习。
。这么多优秀的拍摄构图!光影!还有思路!非常值得学习。但是每次只是收藏,在下一次查看的时候还要点开收藏,翻阅收藏记录,点击查看文章,步骤过于繁琐,而且还有不感兴趣的文字描述和广告,严重影响了我的学习专注度!!!为了提高学习效率,我就一直想着怎么自动把图片保存到本地进行管理,还希望能同步到服务器进行随时随处学习。
自从研究了 selenium 后,对这些需求越来越得心应手。本次主要使用的技术也还是selenium。
基本的思路是:
首先我们从客户端的复制链接开始,点击复制链接,就可以在浏览器打开了。
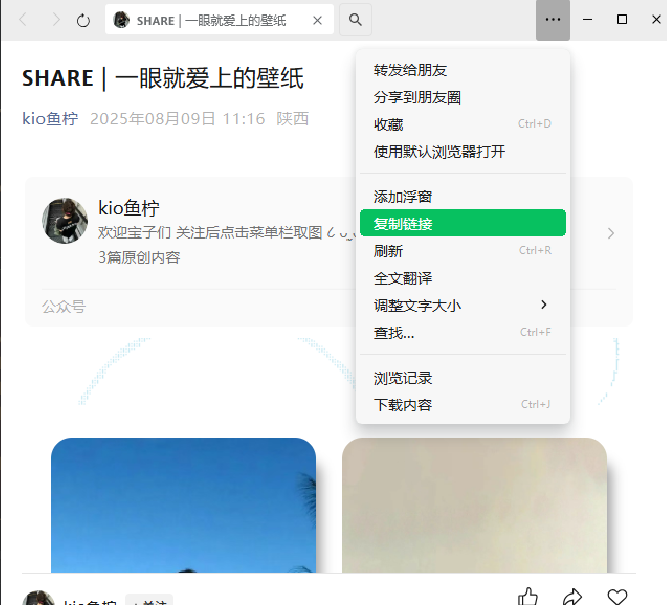
然后我们找到所有图片img标签,可见图片链接在data-src属性下。
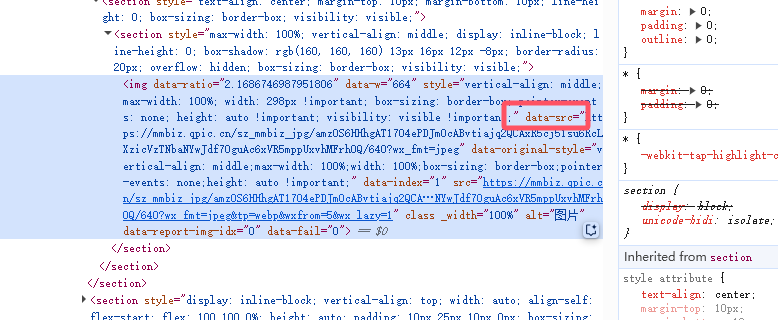
有标签有属性,爬虫起来还是非常简单的。详细的解释可以阅读我之前写的这篇文章 selenium ,我这里直接贴代码。
private static void startOneDownload(String articleLink) {
append("导航至:" + articleLink);
// 无头模式要设置user-agent,否则会被识别到
ChromeOptions options=new ChromeOptions();
options.addArguments("--remote-allow-origins=*");
options.addArguments("--headless");
options.addArguments("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36");
WebDriver driver = new ChromeDriver(options);
driver.navigate().to(articleLink);
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
throw new RuntimeException("FAIL SLEEP");
}
// 查找标题
WebElement titleEl = driver.findElement(By.id("activity-name"));
String title = titleEl.getText();
System.out.println(title);
File file = Paths.get(ROOT, sdf.format(Calendar.getInstance().getTime()) + "__" + filePattern.matcher(title).replaceAll("_")).toFile();
if (!file.exists()) {
file.mkdirs();
}
// 获取图片资源
List<WebElement> img = driver.findElements(By.tagName("img"));
int total = 0;
List<String> links = new ArrayList<>();
for (WebElement item : img) {
String result = item.getAttribute("data-src");
if (result != null) {
total++;
links.add(result);
}
}
append("找到图片:" + total +" 张");
driver.quit();
// 开始下载
int success = 0;
for (int i = 0; i < total; i++) {
String link = links.get(i);
boolean res = download(file.getPath(),(1000 + i) + ".jpg", link);
if (res) success++;
}
append("成功:" + success + " / " + total + "");
}对于TimeUnit.SECONDS.sleep(5);这个本意是用来等待页面装载完成的。不过实际上如果使用 WebDriverWait 类应该也行,这个类可以等待指定元素加载,如果没有加载到继续阻塞,如果重试多次检测都失败则报超时异常。图片保存的名字是用 1000 + i ,之所以用 1000,是为了翻遍对齐字符长度的,这样在浏览的时候所有文件名都是一样长,更加方便阅读。
download函数就是简单的IO流操作,写了不下百遍的代码块了,就是从URL发起http请求,从输入流获取数据到输出流中。
private static boolean download(String basePath, String fileName, String link) {
System.out.println(basePath);
System.out.println("下载:" + link);
try (FileOutputStream os = new FileOutputStream(Paths.get(basePath, fileName).toString())){
URL url = new URI(link).toURL();
HttpURLConnection conn = (HttpURLConnection)url.openConnection();
InputStream is = conn.getInputStream();
byte[] tmp = new byte[1024];
int len;
while ((len = is.read(tmp)) != -1) {
os.write(tmp, 0, len);
}
is.close();
return true;
} catch (Exception e) {
System.out.println("下载失败" + e.getMessage());
return false;
}
}调用任务的是javaSwing技术。界面非常简单,如下所示,布局是经典的borderlayout,南方是输入框,中央区域是消息提示区域。
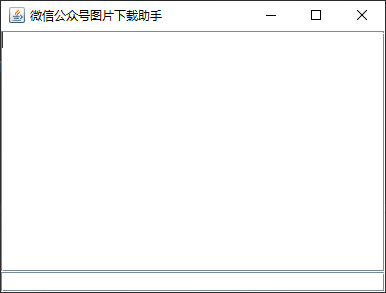
先贴代码再来详解几个注意的细节和小坑。
public static void main(String[] args) {
System.out.println(driverPath);
System.setProperty("webdriver.chrome.driver", driverPath);
JFrame frame = new JFrame("微信公众号图片下载助手");
frame.setLocationRelativeTo(null);
frame.setLayout(new BorderLayout());
frame.setSize(400, 300);
JTextField input = new JTextField();
queue = new LinkedList<>();
input.addKeyListener(new KeyAdapter() {
@Override
public void keyTyped(KeyEvent e) {
if (e.getKeyChar() == '\n') {
String articleLink = input.getText();
input.setText("");
queue.add(articleLink);
append("新入队列,队列排队中: " + queue.size());
// 有新加入的时候,如果线程正在跑,则不管,否则新建线程获取数据
if (thread == null || !thread.isAlive()) {
task();
}
}
}
});
textArea = new JTextArea();
textArea.setEditable(false);
DefaultCaret caret = (DefaultCaret)textArea.getCaret();
caret.setUpdatePolicy(DefaultCaret.ALWAYS_UPDATE);
JScrollPane scrollPane = new JScrollPane(textArea);
scrollPane.setVerticalScrollBarPolicy(JScrollPane.VERTICAL_SCROLLBAR_AS_NEEDED);
scrollPane.setHorizontalScrollBarPolicy(JScrollPane.HORIZONTAL_SCROLLBAR_NEVER);
frame.add(scrollPane, BorderLayout.CENTER);
frame.add(input, BorderLayout.SOUTH);
frame.setVisible(true);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
}
static void task() {
thread = new Thread(() -> {
while (!queue.isEmpty()) {
String link = queue.poll();
if (link != null) {
append("开始任务:" + link);
try {
startOneDownload(link);
} catch (Exception ex) {
append("[EXCEPTION] " + ex.getMessage());
}
append("队列剩余: " + queue.size() + "\n");
}
}
});
thread.start();
}
static void append(String content) {
textArea.append(content + "\n");
}坑:textfield添加keytyped事件,事件无法获得keycode值,始终是0,只能通过获取keychar来获取回车符,所以要用e.getKeyChar() == '\n'来进行判断。细节点:为了使得textarea新增内容时,滚轮重新滑到最底层,需要添加 DefaultCaret 配置。
然后是技术实现上的细节。如何下载?是否使用多线程?我最终选择的是单线程下载,主要的顾虑是如果多线程下载多个任务的话,IO输出上并不好看,然后如果要好看的话,那么又要花不少时间。所以想着一次就只下载一篇公众号文章,就几张图片下载很快,不会遇到什么性能瓶颈。但是在阅览多篇文章的时候,可能每篇都想下载下来,在用户侧这边总不能等待上一个任务全部下载完才继续吧,所以是用户侧不用等待,服务侧等待的机制来实现程序设计。
技术原理就是,每当用户发起一个下载请求时,将该下载请求放入队列,对于下载任务来说,如果队列存在值则继续下载,直到队列空则下载任务结束。下载任务什么时候开始建?当然是在用户发起请求的时候就进行检测,如果当前没有任务或者上次的任务已经关闭了,那么就新启动一个任务开始队列下载,如果下载任务仍然在跑,那么只要请求放入队列,那么上一个正在跑的任务就会读取到,所以无需新增任务来消费。整个执行过程其实是有序的。
最终效果图,还是非常简约风的:
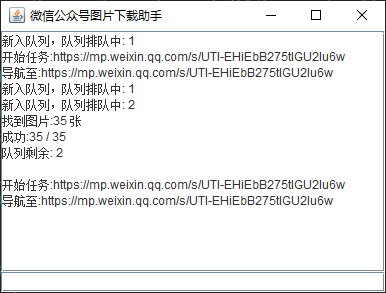
下载的图片也都在硬盘里井然有序的排列着,以供随时学习摄影知识。

当然,项目有上传github,地址点我 。
在这之后,还可以结合openlist、rclone,来将图片同步到云上。比如我的openlist地址:呆呆网盘。游客登录即可查看到内容了,当然可能不会公开太久,过段时间可能就要自己偷偷学习了,所以某天你看到我的呆呆网盘内容和下面截图不一样,不要怀疑,就是我打算独自升级了qwq。
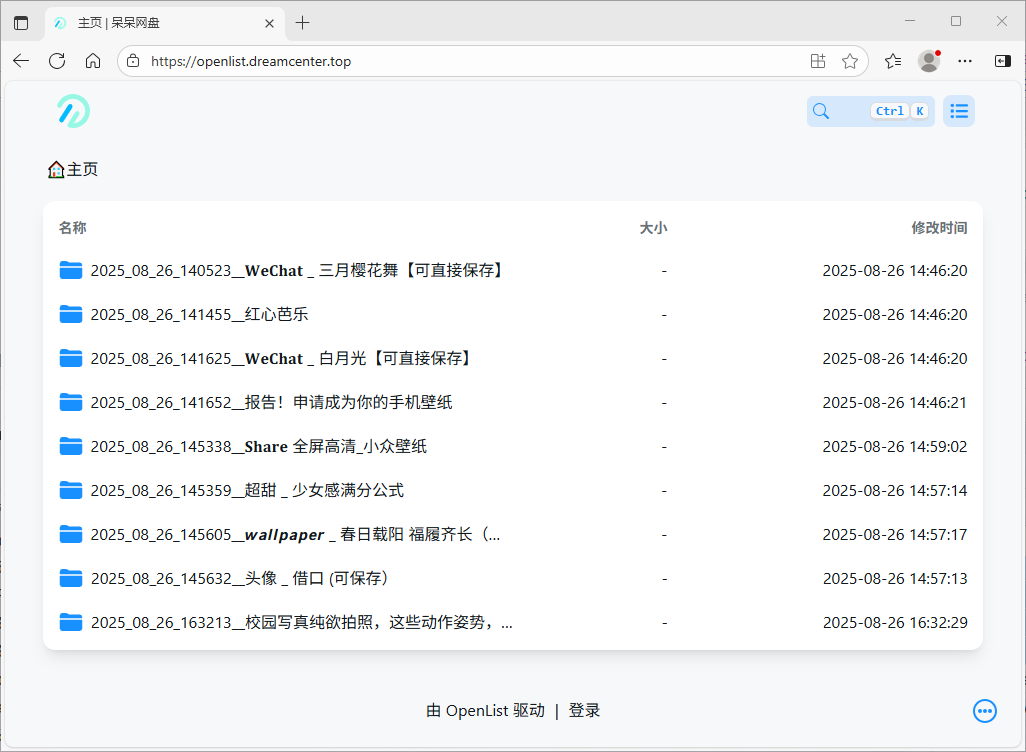
然后关于openlist和rclone后续还会分别有有一篇技术专项研究文章。拖更了几个月了,一直放在待办里(), 敬请期待吧!