RSS,在前文介绍selenium爬虫有捎带提过这个协议,在日常文中也介绍了一篇RSS创始人亚伦的故事,本文就正式的来介绍一下RSS的相关内容,包含 RSS基础概念、订阅源寻找、查阅软件、rsshub搭建指南、个人构建的万用rss框架介绍。
什么是RSS
RSS,(Really Simple Syndication),是一个聚合内容的通用标准,通过RSS,可以将各个不同网站的内容通过一个终端进行访问阅览。比如你既关注微博消息又关注蓝鸟消息还关注博客消息,通过RSS阅览器,可以将三个源只通过一个阅览器就能同时访问到,简化了消息检索和查阅的过程,开拓了一个聚合渠道。
在早期互联网资源珍贵的时候,RSS是一个获取共享知识的绝佳途径,而在如今,互联网的迅猛发展已让RSS逐渐消失在人们的眼中,目前仅活跃在博客之中,原因就是RSS的共享信息精神和新时代知识付费产生了矛盾。
当然RSS作为信息订阅也有一定的局限性。不同于RSS的知识来源死板平面化,现在的互联网让知识发散与聚焦变得更加容易,让知识从面的汇总变化到了多维度层次的深度结合。从发散角度上来看,某个聚合站点比如b站作为视频资讯站(早期的ACGN同好站),在首页上可以看到陈列了各个不同领域板块的内容,加之以用户喜好分析进行智能推荐相关内容,让观者思维可以变得更加开阔。聚焦角度来看,网站通过大数据分析用户浏览偏好结合知识热点,可以不断推荐该领域的知识,引导观者不断的探索知识,让知识变得更加聚焦。除此之外,对于同一类的知识,可供观者的选择性也更多,只是这点孰优孰劣有待商榷,选择性多可能导致难以选择,也可能导致精品内容有更大几率浮现在人们眼前。
如何找到订阅源
订阅源相当于RSS阅览器的门票,只有拥有了这个门票,你才能访问该网站的更新内容。
对于大多数个人博客来说,都有着这样一个图标: 。点击后就可以查看到该网站的RSS订阅地址啦,当然有的网站的RSS订阅源放置的位置会比较隐蔽,如放在 关于页面 或者 页面底部栏 等。目前订阅源路径的格式有很多,无论什么格式,只要内容是符合RSS标准的就好啦,比如我的博客内容RSS地址是 个人博客RSS ,是以xml结尾的静态地址。
。点击后就可以查看到该网站的RSS订阅地址啦,当然有的网站的RSS订阅源放置的位置会比较隐蔽,如放在 关于页面 或者 页面底部栏 等。目前订阅源路径的格式有很多,无论什么格式,只要内容是符合RSS标准的就好啦,比如我的博客内容RSS地址是 个人博客RSS ,是以xml结尾的静态地址。
当然并不是所有的网站都有RSS订阅的,尤其是会员制网站,这些网站的内容往往都具有一定的商业价值,那么是不是就无法通过RSS获取资讯了呢?
那倒也不是,我们依然有其他手段可以获取到,只不过不是官方提供的源罢了。隆重介绍下 DIYGod 的 RssHub,(目前github已经有了38k的★量),官方站点:RssHub,和其他 XxxHub一样,这个RssHub 是聚集了大量订阅源抓取方案的项目,并且社区始终保持着活跃的更新,这个项目几乎涵盖了全网主流站点的订阅方案,如b站、推特、油管、贴吧、微博等等,只需要稍加处理即可(当然并不是所有的都是有效的,毕竟是非官方途径的,大多都是通过爬虫方案解决的,官方网站结构调整或者安全策略变更都会导致失效,需要等待社区更新)。
目前提供的订阅方案隐性的分类主要有两类,一种是无状态的(不需要登录就可以查看到原站内容的),一种是有状态的(指定内容必须通过登录才能够查看到)。
无状态的比较简单,直接使用Rsshub的站点地址拼接即可,比如想要订阅 bangumi番组计划 的每日放送列表,通过在rsshub搜索bangumi后即可找到下图条目,订阅地址为 站点/路由 的方式构成,如下图,首先我们用官方站点rsshub.app,提供的路由是 /bangumi.tv/calendar/today ,那么订阅地址就是:
https://rsshub.app/bangumi.tv/calendar/today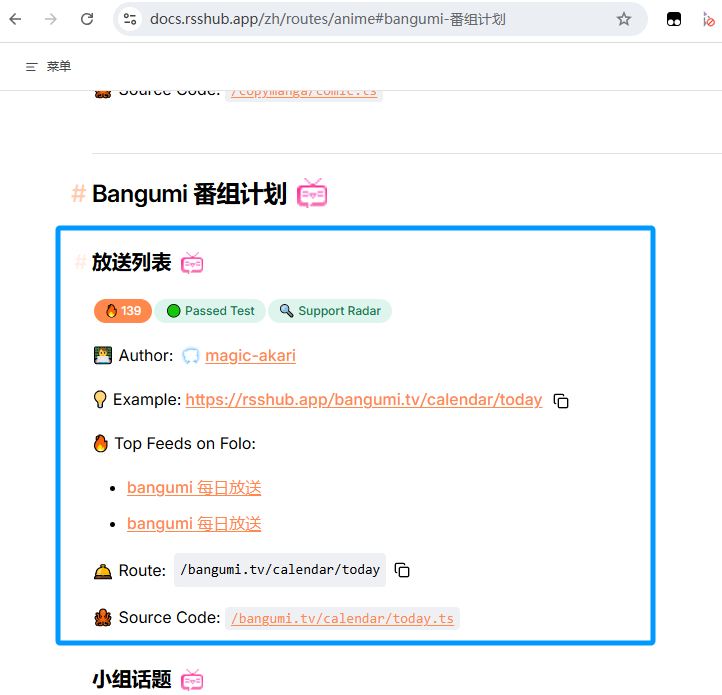
当然上面这个无状态的例子过于简单,再来个带指定用户的无状态例子。比如我想看b站某个up主的视频投稿内容,可以搜索得到下图条目。我们发现在route路由上多了两个参数,一个uid是必填的,指的是b站用户的uid,embed非必填。如果我想查看 夏日幻听MCE 动漫资讯的投稿内容,订阅定制即为:
https://rsshub.app/bilibili/user/video/224267770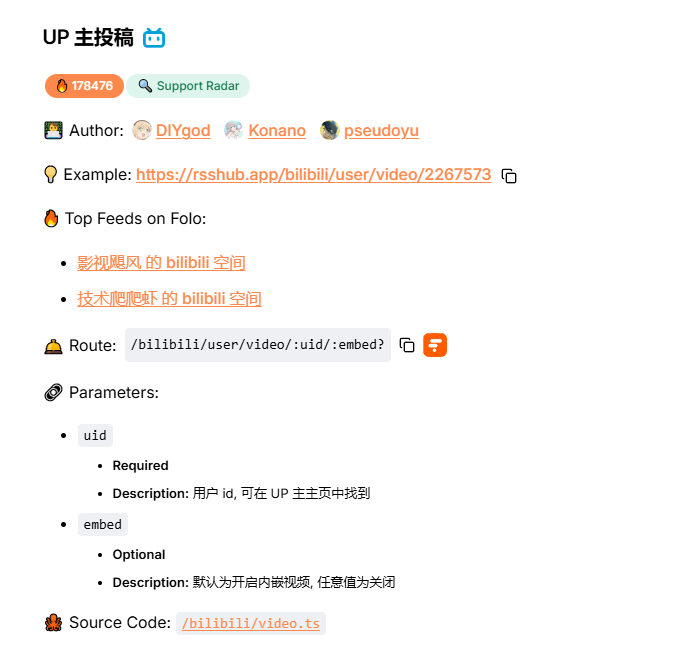
对于有状态类别的方案,就稍显麻烦。这类通常需要自己额外配置一个个人的Rsshub站点,配置上对应的站点cookie才能够正常访问。麻烦不是体现在架设自己的rsshub站点和cookie配置上,而是在cookie随时可能失效。作为订阅源来说属实难受,如果想要稳定订阅,会产生链式架设难度梯升,比如需要获取登录的短信验证码进行登录、绕过“真人”判定的验证机制等。当然,后文会简单的介绍一下如何搭建和配置,至于链式架设方案安全系数较低(比如自动获取验证码是否会导致验证码泄露),暂不推荐使用,这里只做简单的介绍有这种类别。如果有幸找到他人架设的站点,正好提供了特定服务,也可以友好沟通,申请访问通道。
对于Rsshub而言,原作者还开发了一个浏览器插件 RSSHub-Radar,方便查找到浏览页面的相关订阅源。
除了上面的两种方式,也有些其他的个人私建方案,可以自行探索,比如之前流行的wewe-rss,是微信公众号的订阅方案(虽然说现在风控墙导致这个也几乎不能使用了)。
订阅RSS内容的软件
光有“机箱”没有“显示器”也是徒劳,我们通过上面的途径,获得了大批的订阅链接,那么在哪里进行订阅查看呢?这类软件说多不多,但是大多体验较差,直到我发现了它——folo ,(目前github已经有了30k的★量)。又是 DIYGod 的新矛,被称为全世界最好用的RSS订阅软件,拥有着全平台同步的功能,竟然还免费提供服务,属实佩服。
目前仍然是beta版本,虽说仍然有很多的体验不足,但是作为基础使用已经超越了大多数订阅软件了。亮点之多不计其数,先只陈列几点:
- 多端同步(只要登录后,在任何设备访问都是同步的)
- 订阅类别精准划分(可以将订阅源划分成 文章、媒体、图片、视频、通知,使得内容具象化)
- 深度结合Rsshub (对于Rsshub原生的支持非常好,可以直接通过urlscheme rsshub:// 来订阅,内置了rsshub的搜索引擎)
- 与时俱进的AI功能(可以使用AI进行内容概括或者智能翻译,订阅外文再也不用担心看不懂了)
- 文本语音朗读(通过语音朗读,解放眼睛疲劳)
- 简洁的页面(跟随主流设计理念,一切从简)
下载的话不推荐使用微软商店的,目前来看微软商店版安装的folo在更新功能上有问题,建议直接下载通常版本的。下载完成并且注册完账号后即可看到这样的页面了。
然后我们点击上方的“+”号,来到添加导航页。我常用的导航是“搜索”、“RSS”、“RSSHub”,[搜索]可以通过关键词进行搜索,[RSS]可以通过任意的rss订阅链接查询订阅源,[RSSHub]可以直接添加route路由来搜索订阅源。
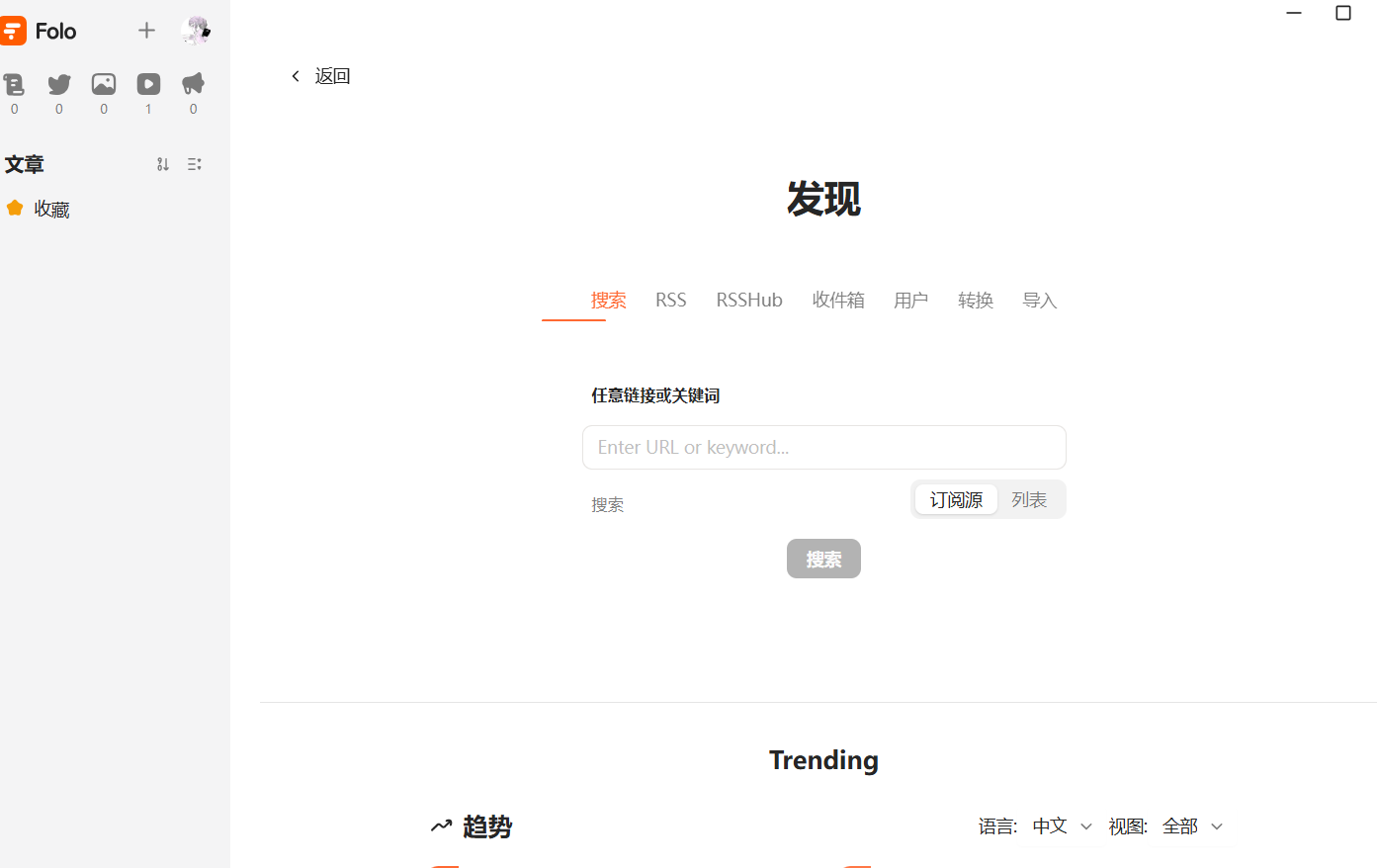
如果搜索成功了,可以进行一些简单的配置,来设置显示的订阅名称、分类,以及想要在哪个视图显示。
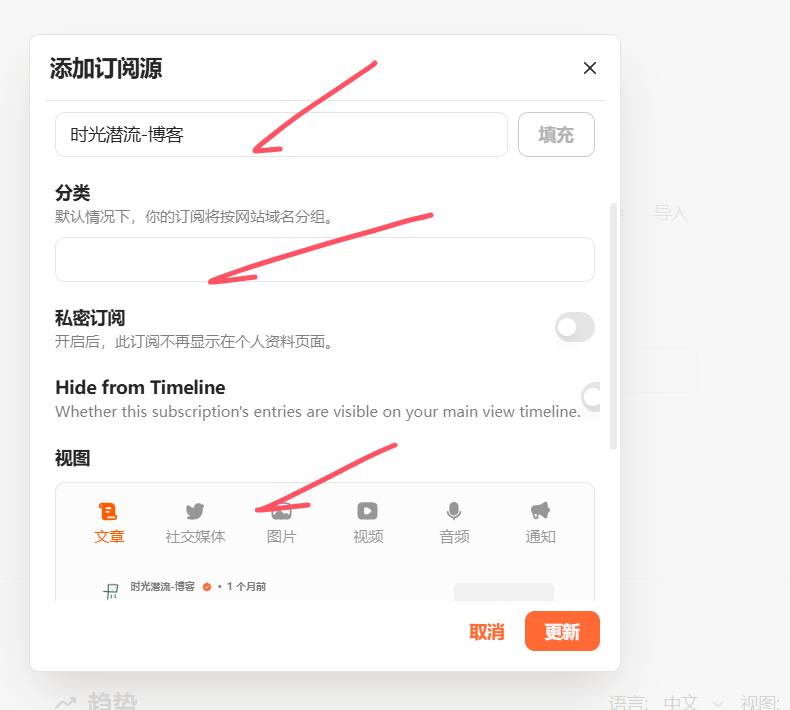
此外还有几个我个人的全局偏好设置可以参考,点击个人头像的设置可以查找到。当然具体怎么设置看个人喜好啦。
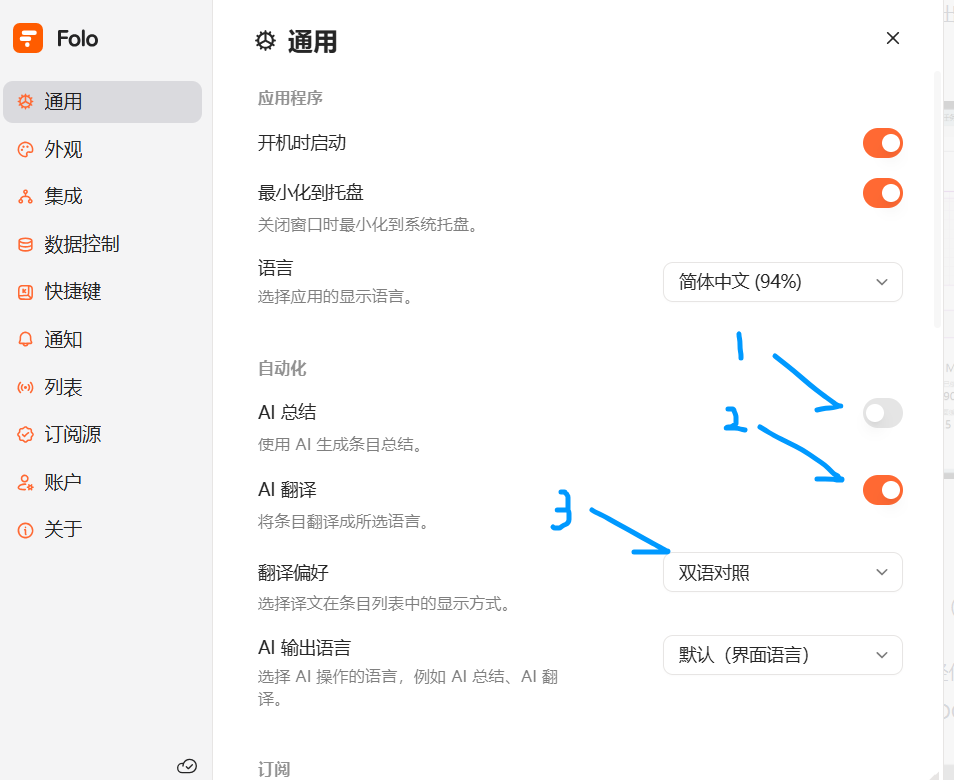
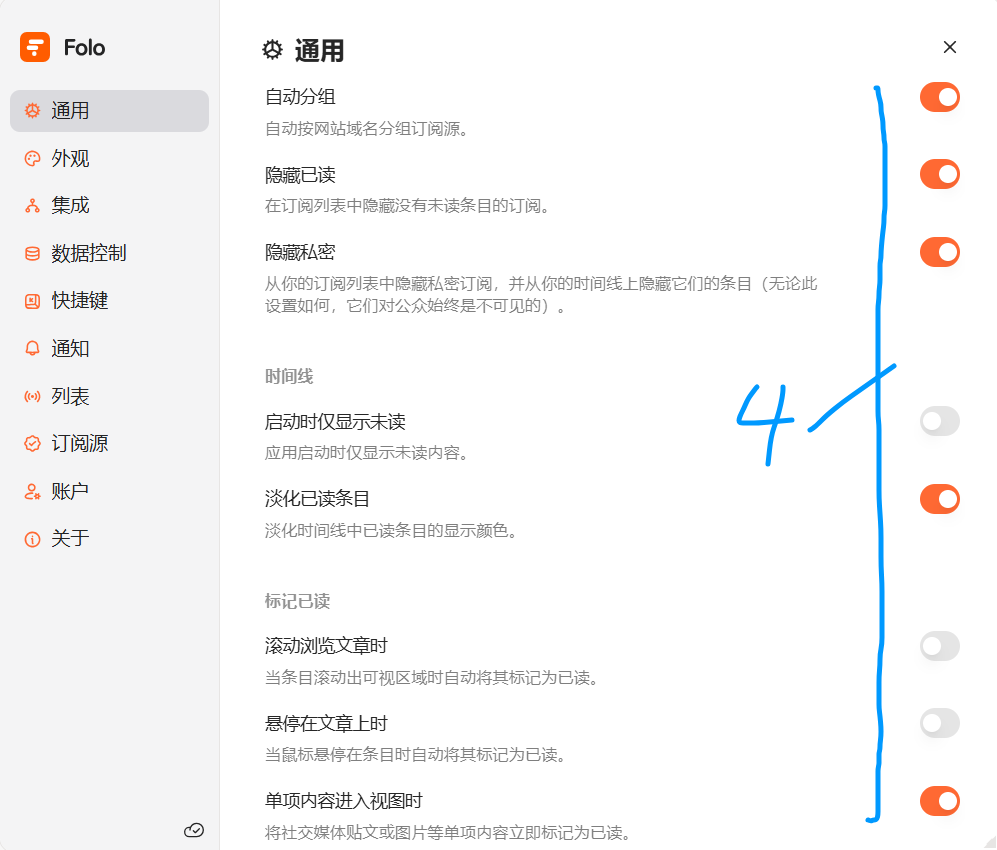
然后是自定义工具栏这。
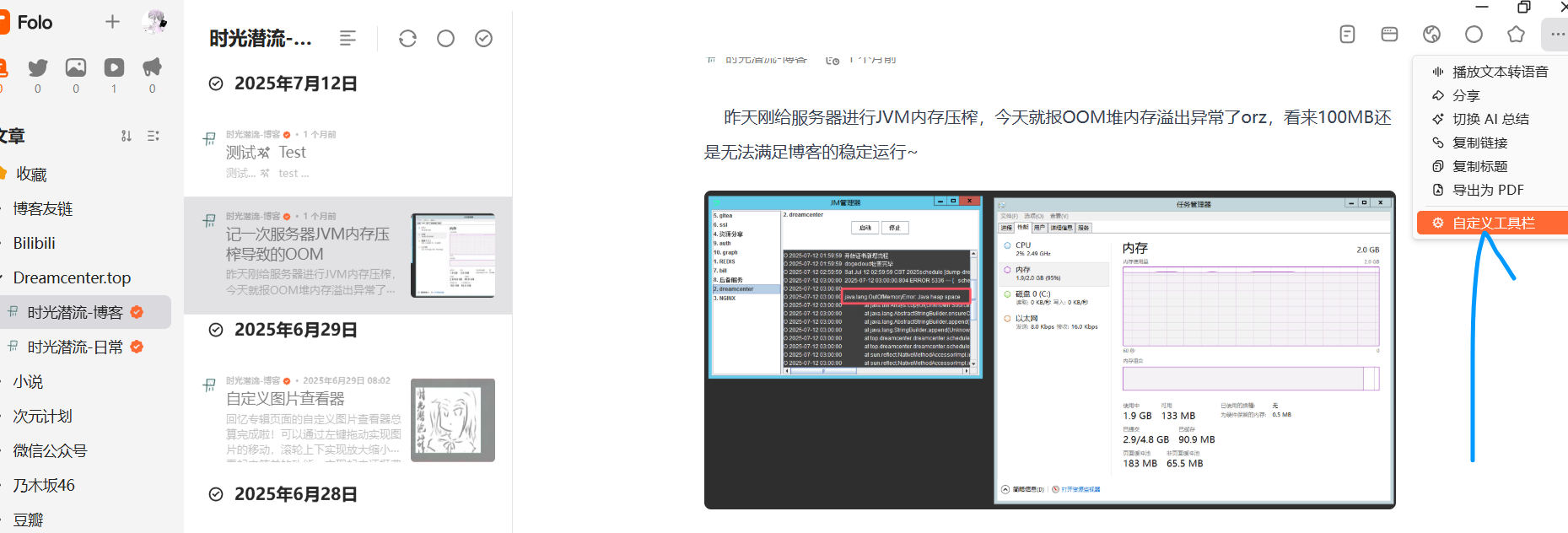
个人推荐只展示这几个即可。阅读模式是文档纯净阅读模式,但是对于后加载数据页面可能无法识别。查看原文是直接在软件内显示原网页。默认打开左侧条目查看到的内容是rss的describe标签的内容,所以推荐个人博客的RSS订阅地址中,关于describe标签尽量贴全文,这样就无需重新解析读取原站点内容了,方便读者查看(相应的原站点击率会下降,看个人取舍)。

至此,作为一个普通的RSS订阅者内容就已经介绍完毕,你已经可以愉快的订阅啦!后文将是针对开发者而言的技术文。
RssHub构建指南
在前文我们简单的介绍了Rsshub的使用方式,接下来来介绍RssHub项目的构建方式。我们可以直接参考官方文档。我这里只展示两种方法。
zeabur一站式部署
自己的服务器性能已经无法再部署一个Rsshub?可以试试zeabur来一键部署(非广,在若干一站式部署中找到的唯一可以长久白嫖的网站,故推荐),每个月都有1美刀的免费额度,只是搭建Rsshub足够了,目前可以稳定白嫖。
点击链接,可以来到Rsshub模板页面。之后选择地区和域,点击确认即可。
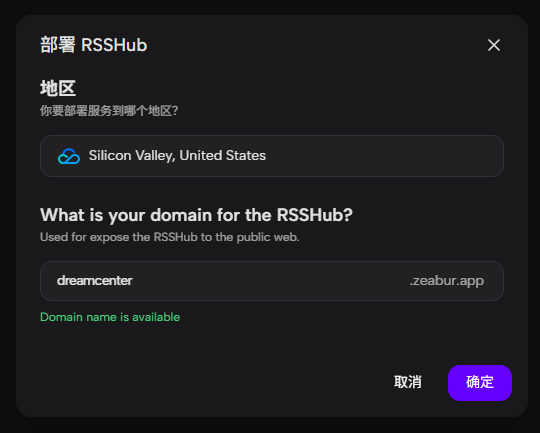
之后。来到项目位置,如果Rsshub服务的小窗有图示的页面呈现,那么就说明部署成功了,点击域名即可来到Rsshub主站点,之后所有的订阅地址都可以用 域名/路由 来订阅,和Rsshub官网一致,只是换成了个人域名而已。一般来说等程序稳定后,资源用量一个月大概就在1$左右。
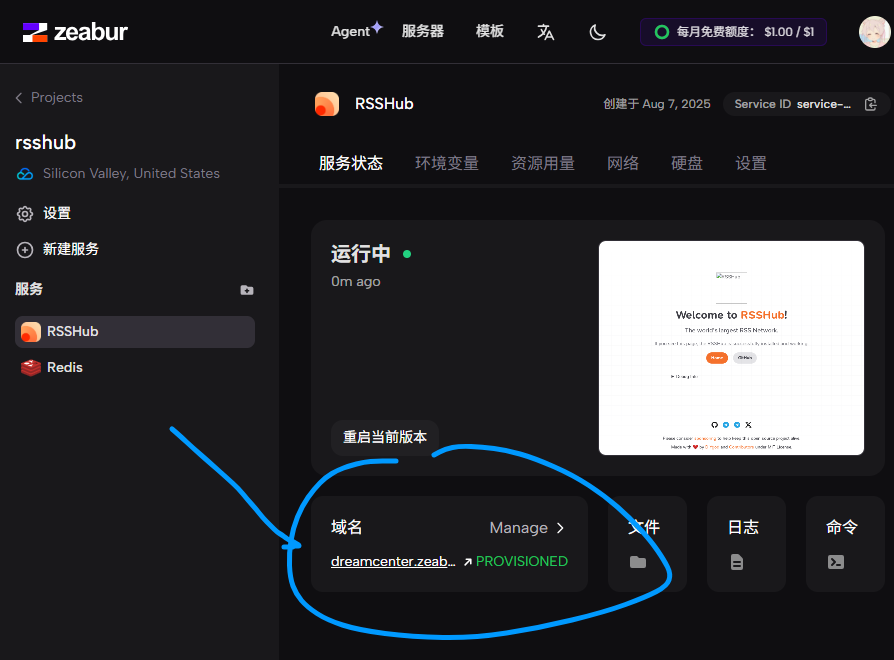
只是这样搭建其实没有意义,我们主要还是想要有状态的站点服务,比如我们想要订阅小红书用户的内容。我们先来到Rsshub官网,找到小红书模块,发现了 ⚙Config Required 标记,集表示该订阅需要额外配置,看到下方Deployment Configs中,可以看到需要加上 XIAOHONGSHU_COOKIE 的配置项。
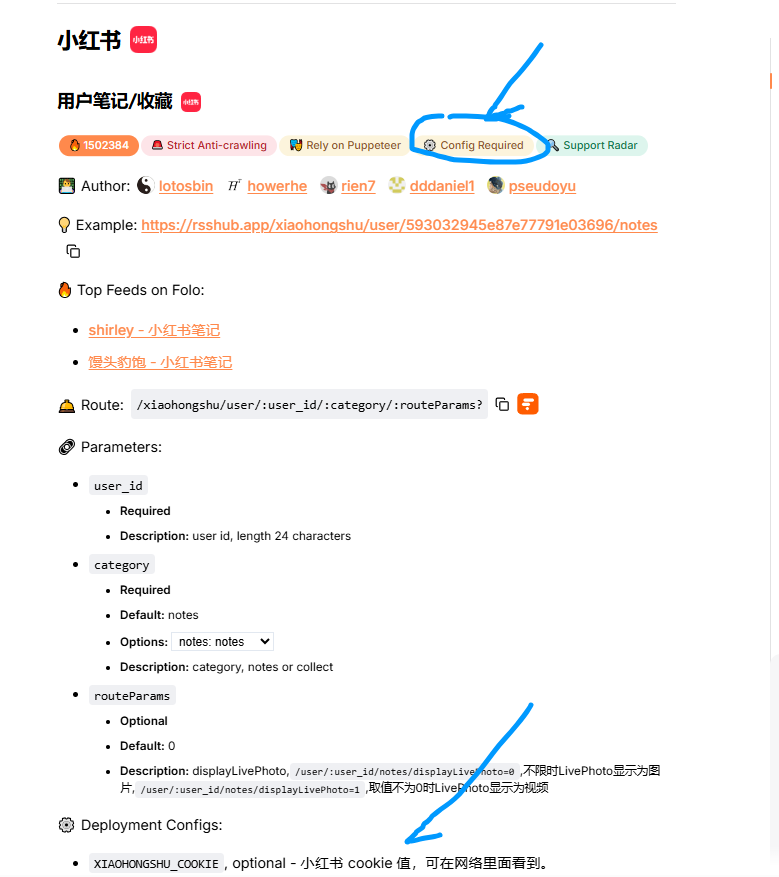
为了获取到cookie,我们先登录网页端的小红书,来到个人页面,在控制台的网络中就可以找到带cookie的请求,我们复制这个cookie。
abRequestId=c4f30267xxxxxxxxx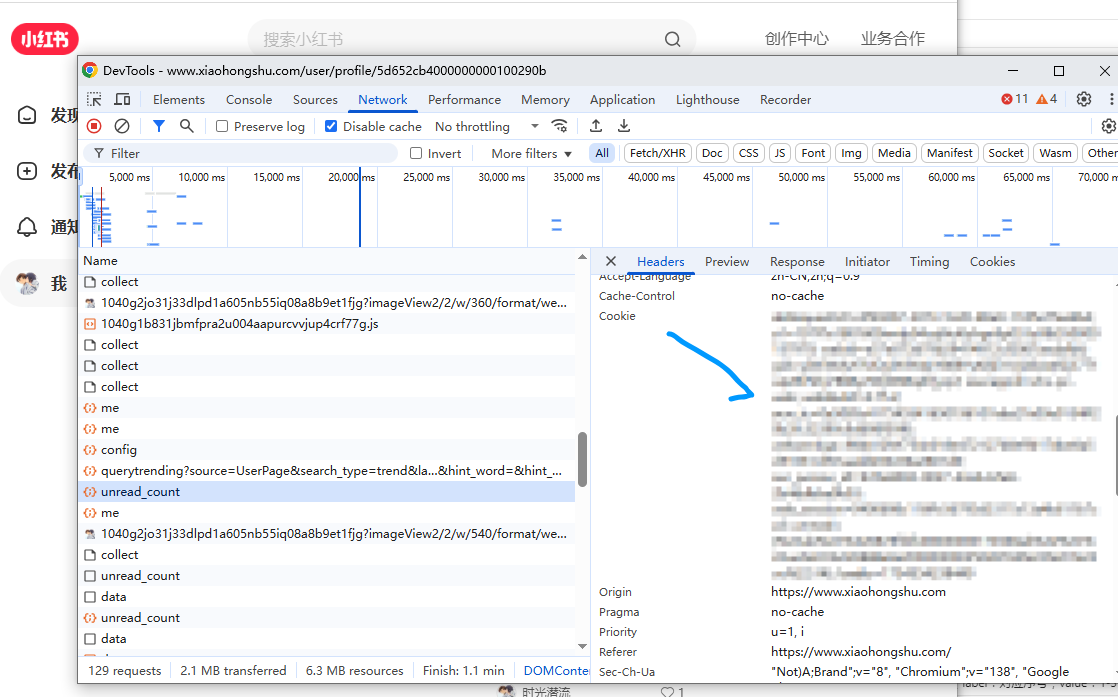
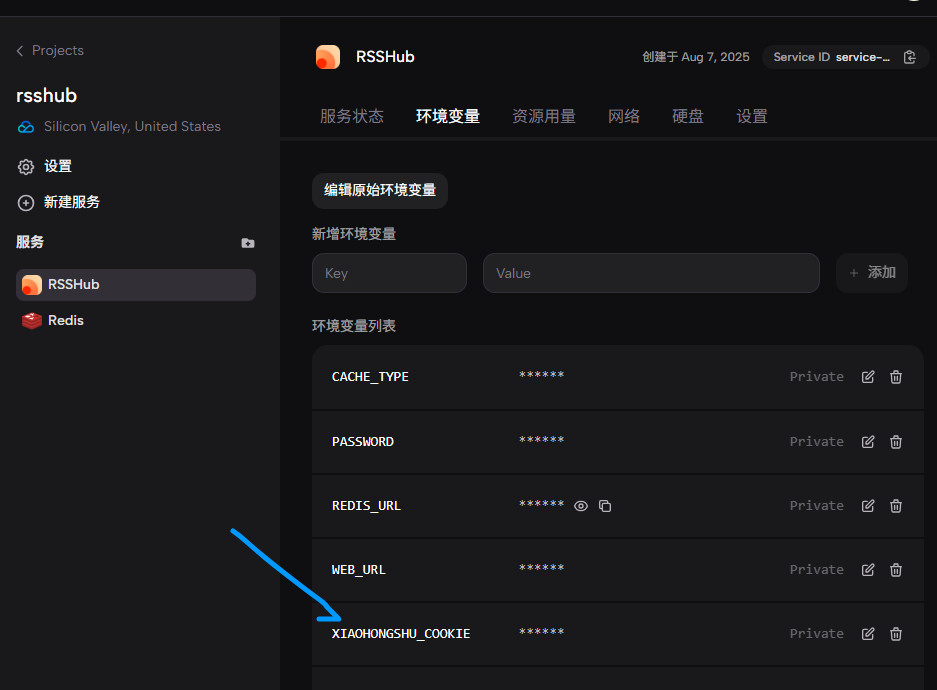
回到我们的zeabur的环境变量页签,加上cookie配置,并且重启RSSHub服务,即可部署成功。
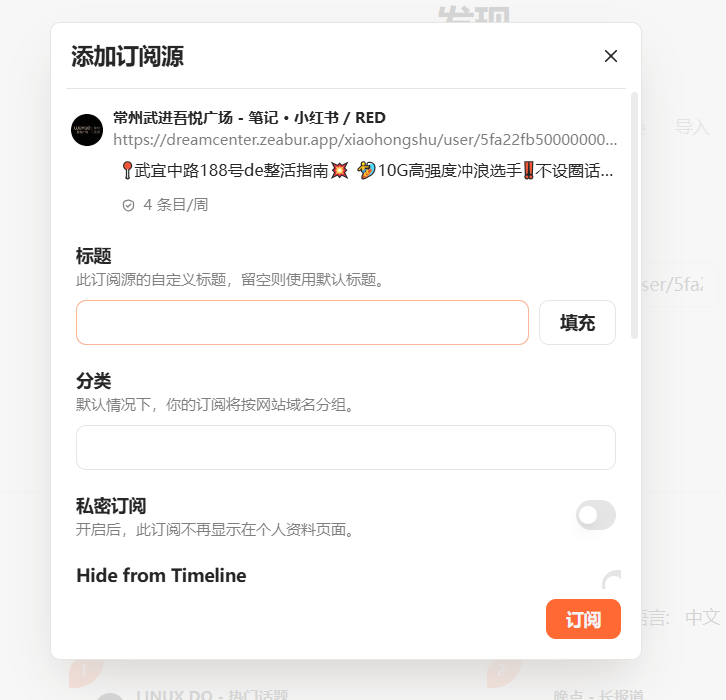
我们随便找一个小红书用户,比如我想要关注武进吾悦的内容,先找到id为 5fa22fb5000000000101dfe0,那么订阅的路由就是:
/xiaohongshu/user/5fa22fb5000000000101dfe0/notes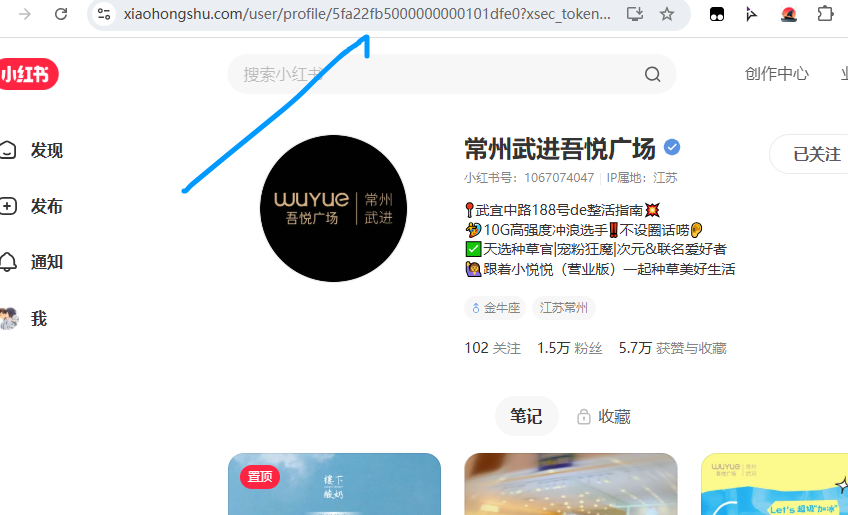
结合zeabur提供的域名,地址即为:
https://dreamcenter.zeabur.app/xiaohongshu/user/5fa22fb5000000000101dfe0/notes放入folo预览,即可发现小红书内容获取成功了(不过貌似cookie过期时间挺短的说~这里只做示例)。
宝塔docker部署
上面的毕竟是三方的服务,稳定性并不能保证,如果自己的服务器资源充足,那么可以直接在自己服务器的docker上进行部署。
推荐使用docker compose部署。可以直接参考rsshub官网教学。
先下载docker-compose文件。
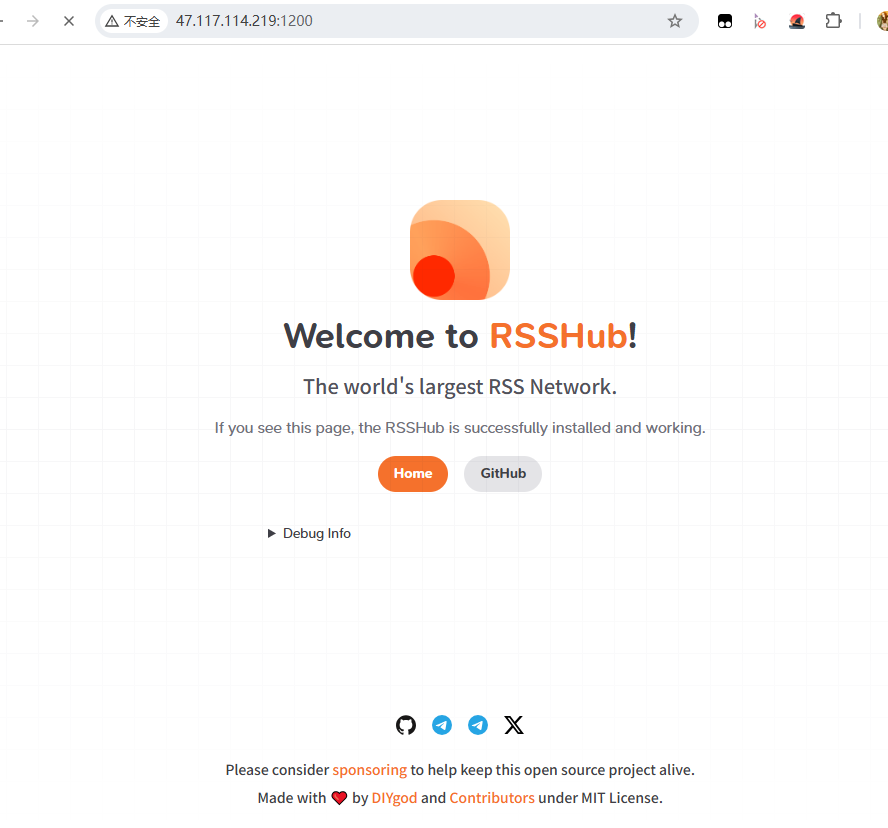
wget https://raw.githubusercontent.com/DIYgod/RSSHub/master/docker-compose.yml检查配置没有问题后直接启动。
docker-compose up -d访问1200端口(防火墙放行或者自行配置nginx),出现下图即为正常启动。
同样的,我们想要访问小红书,该怎么配置呢?
首先我们先停止上面的服务。
docker-compose stop我们来配置下载下来的docker-compose文件。加上我们的配置参数后,重新执行下面命令即可。
docker-compose up -d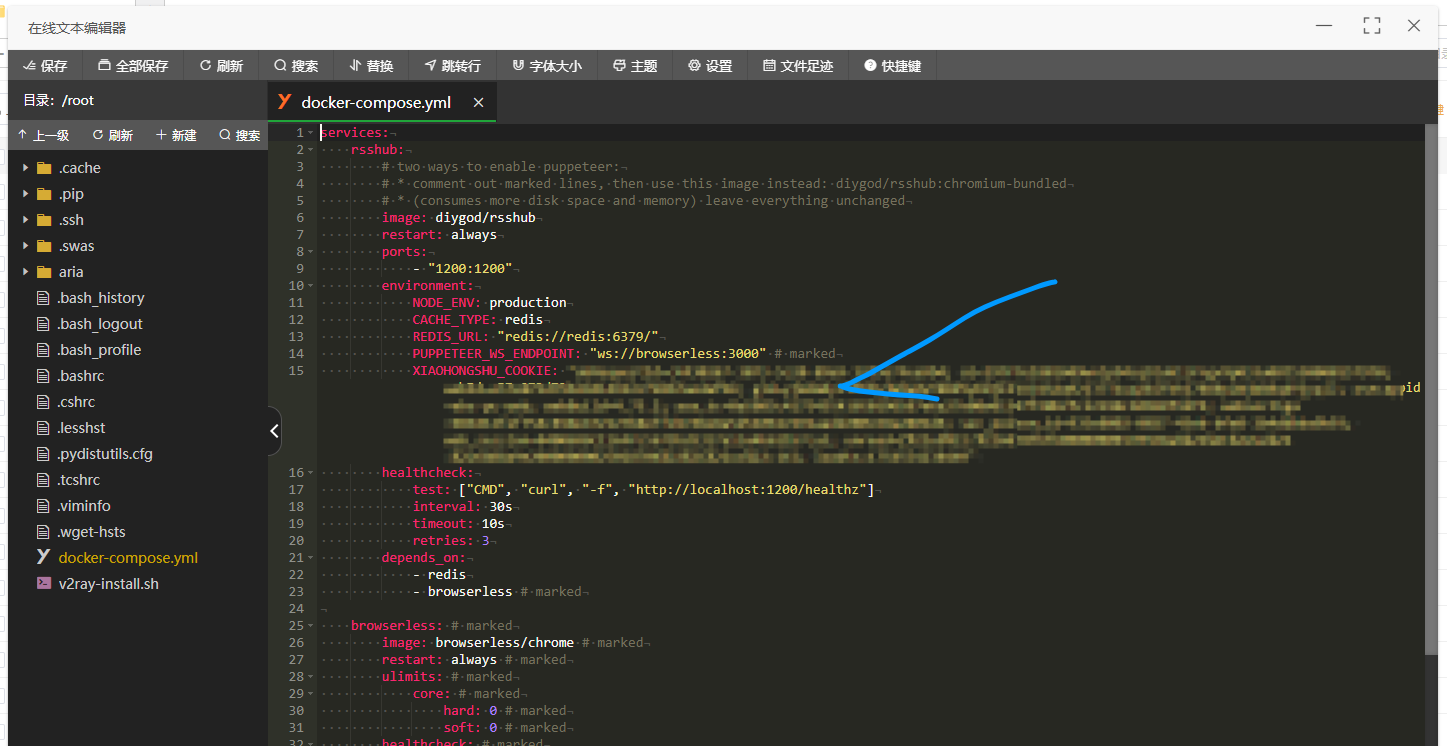
这次我们浏览器直接来访问订阅地址,发现也成功获取到了。
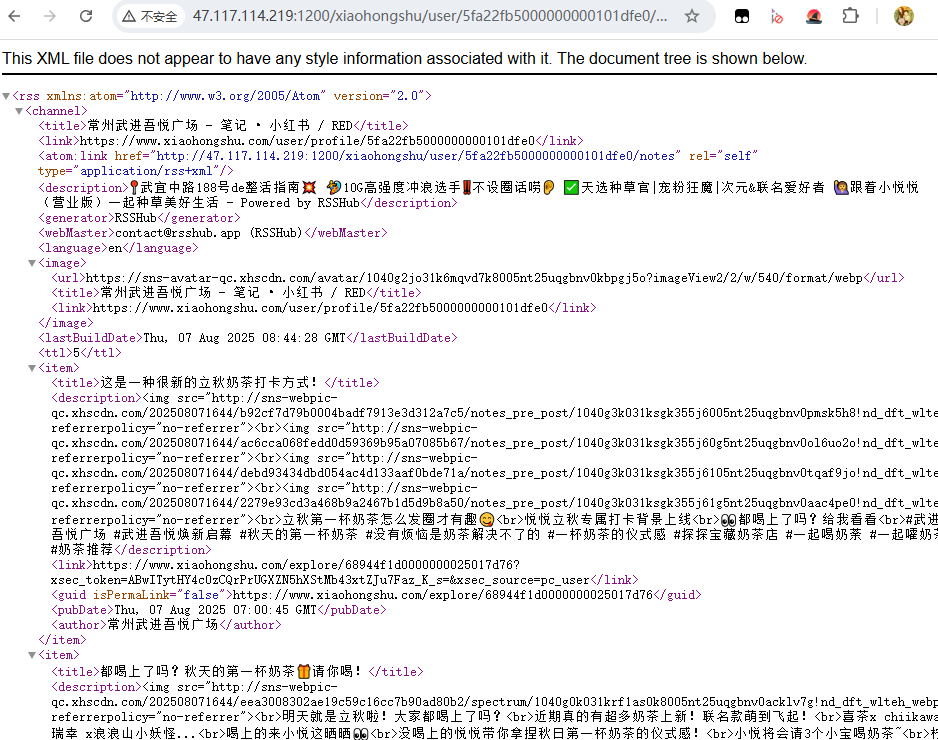
这样就可以愉快的玩耍啦!
个人构建RSS万用框架
如果你会Node.js开发,只用rsshub进行扩展开发应该足够应付绝大部分的场景。但是如果是复杂的场景,rsshub仍然有些力不从心,至此,我就用springboot构建了一套自定义爬虫RSS框架,如果你熟悉springboot,可以参考。
当然了,现在该项目还只是draft草案阶段,框架多多少少有些不完善的地方,所以说只做参考。设计的思路是插件化开发。后端web程序提供基础逻辑实现,负责对爬虫插件的管理和调用。
对于主程序来说,可以从plugins目录下 装载合适的插件,一个插件拥有以下几个基础属性:
pluginId: 组件容器注册名
cron:组件定时任务执行表达式
route:组件路由地址
key:用户key(如爬虫页面用户的uid列表,该列表下的数据会一同处理)
config:支持额外的配置,以供组件调用(如cookies等)
至于插件的开发要分三步走:
- 插件主类继承 RegisterSpider 协议接口
- 插件类添加注解 @RegisterSpider 表示要注册到容器中
- 配置META-INF,注册插件配置信息
仅实现了RegisterSpider的类才视为合法的插件
仅包含了@RegisterSpider的插件才会被注册到容器
仅配置文件注册了的插件类才会被ClassLoader装载
插件的META-INF,需要添加配置文件rss_spider。 文件内容的格式类似于spring.factories,以下仅为示例:
plugins=top.dreamcenter.rss.rsssolverpluginxhs.XhsSpider,top.dreamcenter.rss.rsssolverpluginxhs.WxSpider
这样,后续我们只要实现接口协议即可自定义开发任何想要适配的插件(具体的selenium使用方式参见博客:Selenium工具爬取数据 | 万用RSS )。
至此全文关于RSS的探讨就已经告一段落啦!希望你能在rss的海洋徜徉~